本文译自Top 10 Strategic Technology Trends for 2020, Published on 21 October 2019. ID: G00432920. Analysts: David Cearley, Nick Jones, David Smith, Brian Burke, Arun Chandrasekaran, CK Lu
基本上是全文照译。为了加强理解,我们加入了一些名词解释。
[空行]
[空行]
[空行]
战略技术趋势具有创造机会和推动重大颠覆的潜力。企业架构和技术创新领导者必须评估这些主要趋势,以确定趋势组合如何推动创新战略。
战略技术趋势具有巨大的潜力,可以创造和应对颠覆,并推动转型和优化计划。
人工智能(AI)能够从基础上催化高级流程自动化以及团队扩充与赋能。
工厂、办公室和城市等物理环境将成为“智能空间”,人们将在其中通过多个接触点和感官渠道进行交互,从而获得越来越多的环境体验。
如何应对人工智能、物联网(IoT)、边缘计算和其他不断发展的技术所产生的隐私、数字道德和安全所带来的挑战,对于维持信任和避免法律纠纷至关重要。
企业架构和技术创新领导者必须:
将创新工作聚焦在人,并使用用户画像、旅程图、技术雷达和路线图等工具来评估合适的机会、挑战和时机。
构建跨越功能和流程孤岛的总体视图,并利用一组辅助工具,包括RPA、iBPMS、DTO,应用开发和人工智能,以指导如何使用工具、如何集成创建的系统。
拥抱多元体验、实施开发平台和设计原则,以支持对话式、沉浸式和日益增长的环境体验。
建立治理原则、政策、最佳实践和技术架构,以提高有关数据和使用人工智能的透明度和信任度。
[空行]
[空行]
[空行]
战略规划假设
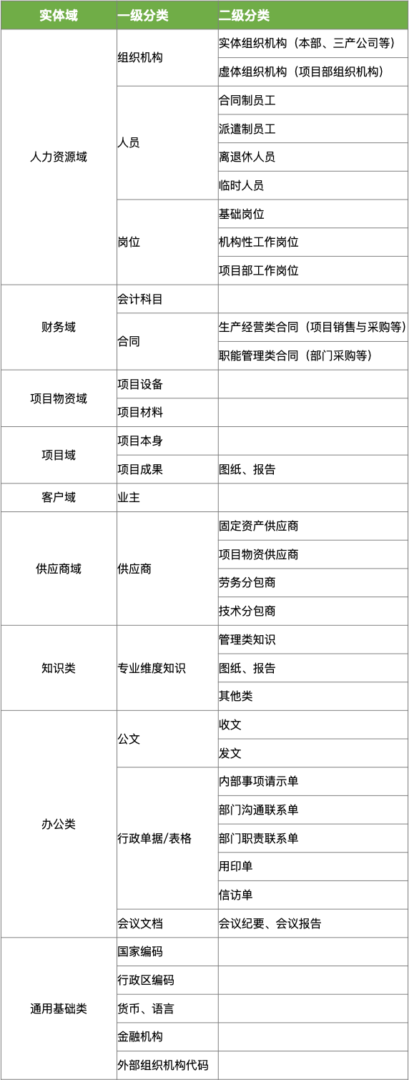
构建以人为本的智能空间
趋势1:超自动化(Hyperautomation)
趋势2:多元体验(Multiexperience)
趋势3:民主化(Democratization)
趋势4:人类增强(Human Augmentation)
趋势5:透明度和可追溯性(Transparency and Traceability)
趋势6:赋权边缘(The Empowered Edge)
趋势7:分布式云(Distributed Cloud)
趋势8:自主物件(Autonomous Things)
趋势9:实用区块链(Practical Blockchain)
趋势10:AI安全(AI Security)
[空行]
[空行]
[空行]
[空行]
到2022年,将有70%的企业尝试使用沉浸式技术供消费者和企业使用,而25%的企业已将其部署到生产中。
到2022年,培训和模拟行业中35%的大型企业将评估并采用沉浸式解决方案,而2019年这一比例不到1%。
到2021年,至少三分之一的企业将部署多元体验开发平台,以支持移动、Web、对话和增强现实开发。
到2024年,75%的大型企业将至少使用4个低代码开发工具来进行IT应用开发和公民开发计划。
到2022年,至少40%的新应用开发项目将在团队中拥有人工智能合作开发人员。
到2021年,数据科学任务的自动化,将使公民数据科学家能够比专业数据科学家进行数量更多的高级分析。
到2025年,数据科学家的稀缺将不再阻碍组织采用数据科学和机器学习。
到2022年,将有30%的使用AI进行决策的组织,将影子AI视为有效和道德决策的最大风险。
到2023年,有30%的IT组织将通过“自带增强功能”(BYOE)扩展BYOD策略,以解决员工队伍中的增强人群。
我们预计,到2020年,拥有数字化信誉的公司将比没有数字化信誉的公司多产生20%的在线利润。
我们预计,到2020年,全球4%的基于网络的移动通信服务提供商(CSP)将商业化推出5G网络。
到2024年,大多数云服务平台将至少提供一些在需求点执行的服务。
到2023年,区块链将在技术上可以扩展,并将支持数据保持必要机密的可信私有交易。
到2022年,超过75%的数据治理计划将无法充分考虑AI的潜在安全风险及其影响,从而导致可量化的财务损失。
到2022年,所有AI网络攻击中的30%,将利用训练数据中毒、AI模型失窃或对抗性样本来攻击AI驱动的系统。
[空行]
[空行]
[空行]
[空行]
Gartner的2020年十大战略技术趋势(图1)突出了企业在五年战略技术规划过程中需要考虑的趋势。这些趋势会对人及其居住空间产生深远的影响。战略趋势对各个行业和地区具有广泛的影响,并且具有很大的颠覆潜力。在很多场合,战略趋势尚未得到广泛认可,或者对待的传统观念正在失去作用(请参阅附注1)。
战略技术趋势为渐进式、变革型甚至颠覆性创新创造了机会。公司必须检查这些趋势对业务的影响,并适当调整商业模式和运营,否则会有失去竞争优势的风险。以下是由于各种原因不能忽视的一些趋势:
与战术(今天)、新兴(5至10年)和远景(10年以上)的差异
[空行]
到2025年,与这些趋势相关的技术将发生重大变化,跨越关键的引爆点,并达到新的成熟度,从而扩大和实现可重复使用的用例,并且降低风险。技术创新领导者必须研究十大战略技术趋势的商业影响,并且抓住机遇改进现有流程,或创建新流程、产品和商业模式。你必须为这些趋势的影响做好准备,因为它们将改变行业和你的企业。
图1 2020年十大战略技术趋势
作为ContinuousNext战略[1] 的一部分,十大战略技术趋势是推动持续创新过程的关键要素。技术创新领导者必须采用能够适应和接受持续变化的思维方式和最新实践。变革可能是渐进的、也可能是激进的,并且可以应用于现有或新的商业模式与技术。
ContinuousNEXT是Gartner提议的一项业务战略,旨在敦促企业将变更管理作为所有企业经营的组成部分。ContinuousNEXT强调永续创新、集成和交付,是数字化转型的的下一个进化阶段。
根据Gartner的定义,ContinuousNEXT战略包含五大要素:
文化:建立鼓励员工接受持续改进的企业文化。在技术方面,这可能包括采用连续开发(CD)、连续部署、连续集成(CI)、连续质量(CQ)、连续数据保护(CDP)和连续备份(CB)。在人力资源管理中,这可能包括连续绩效管理(CPM)。
隐私:通过包含适度隐私控制的企业隐私计划,来维持消费者的信任。
增强智能:专注于人工智能的辅助作用,强调AI旨在增强人类智能、而不是替代人类的事实。
数字产品管理:将科技融合到公司运营的方方面面。
数字孪生:通过对系统、流程和员工交互进行建模,创建组织数字孪生(DTO),向利益相关者提供组织运作方式的高阶视图。
[空行]
技术正在改变人们的生活,使业务持续数字化,并推动组织不断刷新商业模式。在迈向数字化的漫长过程中,技术正在以不断提高的速度放大连续变化。组织需要考虑如何在两个连续而互补的周期中应用这些战略趋势:
趋势和技术并不是孤立存在的。它们相互依存、相互加强,共同创造了数字世界。组合创新探索了趋势组合,以构建更大的整体方式。各种趋势和相关技术正在组合起来,逐步实现智能数字网格中体现的整体愿景[2] 。例如,机器学习(ML)形式的AI与超自动化和边缘计算相结合,实现高度集成的智能建筑和城市空间。反过来,业务用户和客户自助服务需要满足个性化需求,使技术的应用进一步民主化。 CIO和IT领导者面临许多“困境”,例如交付现有服务和创新新型服务。你可以通过“思考”将“困境”转变为“机会”,多种趋势的综合作用能产生新的机会、推动新的颠覆。组合式创新是我们2020年十大战略技术趋势的标志。
未来将以智能设备为特色,提供无处不在、且日益增长的智慧数字服务。我们称其为“智能数字网格 (intelligent digital mesh)”。它可以描述为:
智能 主题探讨AI(尤其是机器学习)是如何渗入几乎所有现有技术、并创建全新技术类别的。到2022年,AI的利用将成为技术提供商的主战场。将AI用于范围明确且有针对性的目的,将提供更加灵活、更有洞察且日益自主的系统。
数字 主题的重点是融合数字世界和物理世界,以创造自然和身临其境的数字增强体验。随着物件产生的数据量呈指数增长,计算能力转移到边缘设备,以处理流数据、并将汇总数据发送到中央系统。数字化趋势以及AI带来的机遇,正在推动创建下一代数字业务和数字业务生态系统。在这个智能的数字世界中,会生成大量的丰富多样的数据,因此需要更加关注数字道德和隐私,以及它们所要求的透明性和可追溯性。
网格 主题是指利用不断扩大的个人和企业(以及设备、内容和服务)之间的连接,来提供数字化业务成果。网格需要新的能力,以减少摩擦、提供深入的安全性,并响应这些连接上的事件。
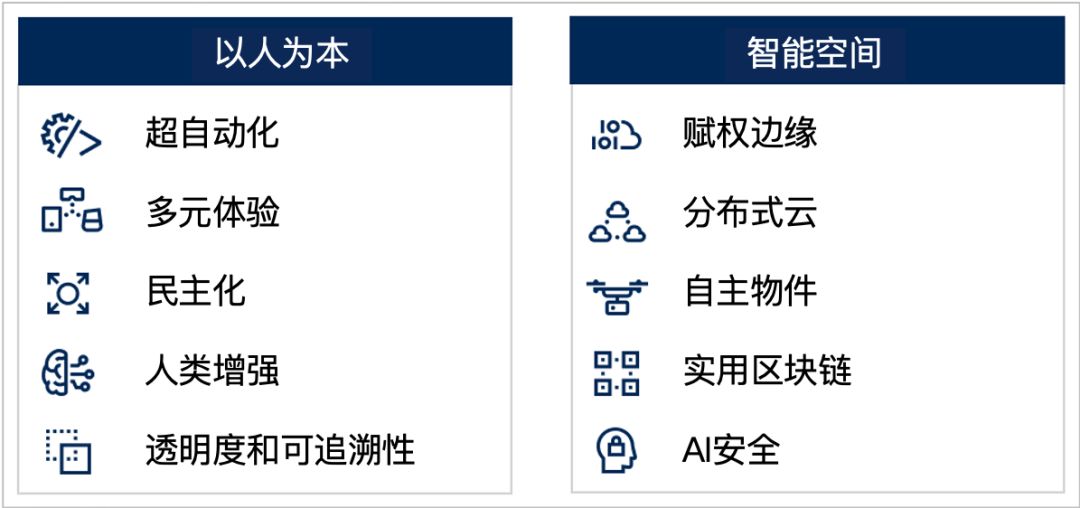
过去数年,智能数字网格一直是Gartner战略技术趋势的始终不变的主题,未来五年它将继续作为重要的潜在力量。但是,此主题侧重于趋势的技术特征。同样重要的是将趋势放在将要受到影响的个人和组织的背景下。组织必须先考虑业务和人员环境,而不是构建技术栈,然后探索潜在的应用程序。我们称其为“以人为本的智能空间 ”,并用此结构组织和评估2020年战略趋势的主要影响(图2)。
图2 以人为本的智能空间
将人置于技术战略的中心,突出显示了技术的最重要影响之一:它如何影响你的客户、员工、业务合作伙伴、社会或其他关键群体[3] 。以人为本的方法,应该从理解与组织进行互动和支持的关键领域和旅程开始。这是了解如何、在何处应用战略技术趋势,以实现预期业务成果的第一步:
用户画像 (Persona):
用户画像是描述目标个人或群体的有用工具。用户画像封装了一组动机、偏好、偏见、需求、欲望、愿望和其他特征,可以用作评估技术应用如何影响用户群体的背景。用户画像已经使用很多年,在设计和营销领域得到了最广泛的采用,是这些领域了解目标受众的动机的重要手段[4] 。用户画像为评估对人的潜在影响、以及由此产生的业务成果奠定了基础。用户画像可以用来预测人们穿越技术支持的智能空间时将出现的宝贵业务时刻[5] 。基于用户画像的分析是帮助领导者诊断和行动、应对数字化业务颠覆机会的强大工具。企业架构和技术创新领导者可以帮助业务和IT负责人考虑用户画像扮演的数字化业务战略决策的人性面。
旅程图 (Journey Map):
第二个有用的工具是定义旅程图。旅程图是显示目标人群完成任务或完成过程各阶段的模型。客户旅程图描绘客户在购买产品、访问客户服务或在社交网络上抱怨公司的过程。你还可以考虑内部旅程图,描绘员工入职或遵守法规要求所经历的阶段。考察多个领域如何围绕一个流程进行交互的旅程图更加强大。例如,客户购买的旅程图可能不仅考虑客户视图,而且考虑销售或配送的视图。旅程图为技术驱动的创新提供了更为具体的环境。技术创新专业人员应考虑痛点、效率、差距和机会,以使所有相关人员乐于创造新的数字业务时刻。
智能空间的概念基于以人为本理念构建。人们存在于房屋、汽车、办公楼、会议室、医院或城市的空间中。智能空间是人类和技术驱动的系统在日益开放、连接、协调和智能的生态系统中相互作用的物理环境。人、流程、服务和物件等多种元素在一个智能空间中汇聚在一起,为目标用户创建更加身临其境、互动和自动化的体验。旅程图不仅应考虑相关用户的动机和期望的业务成果,而且还应考虑人们在数字世界中作为交互的一部分所经过的空间。
以人为本的智能空间,代表了应用技术趋势的核心目标。技术创新领导者应围绕中心考虑同心圆的趋势,从直接接触人类的趋势、发展到因衍生影响而更加隐蔽的趋势。从中心出发、从人为出发点,最终集中于后端基础架构,这是对传统自下而上的技术栈观点的微妙而有用的改变。从中心向外推动的架构,可确保各个层级的需求均由业务成果驱动,并且该架构更具有内在的适应性:
人通过边缘设备及其上的多种用户体验(界面)与他人以及数字空间进行交互,这是他们日常生活的自然组成部分。
应用、服务和生态系统通过边缘设备和体验,为智能空间中的人提供价值。
开发工具、数字平台、数据、AI/ML服务、集成和相关技术,用于创建可通过边缘设备提供价值的应用和服务。这些工具为创建应用、服务和生态系统提供了动态、灵活和模块化的基础。
基础设施、运行、网络和安全是构建技术驱动世界的基础。它必须最终为人提供支持,因此必须在每个层面上创造价值。
我们将2020年的十大战略技术趋势分为以人为本和智能空间两大类。这是一个松散的结构,旨在传达将在哪里看到趋势的主要影响和体现。但是,几乎所有趋势都会对人和智能空间概念产生影响。
超自动化 (Hyperautomation)
处理人工智能和机器学习等先进技术的应用,使流程越来越自动化、并增强人的能力。
多元体验 (Multiexperience)
涉及人在各种设备和感官接触点上感知、交互和控制数字世界的方式。
民主化 (Democratization)
探索如何创建简化的模型,供人使用数字系统、并利用培训或经验之外的自动化专业知识。
人类增强 (Human augmentation)
探索这些系统如何在生理和认知上增强人类能力。
透明度和可追溯性 (Transparency and traceability)
着眼于数据隐私和数字道德挑战以及设计、操作原理和技术的应用,以提高透明度和可追溯性,从而增强信任。
智能空间 (Smart Spaces):
赋权边缘 (Empowered edge)
强调人们周围的空间如何越来越多地被传感器和设备连接起来,它们建立了人们彼此之间、数字服务之间的联系。
分布式云 (Distributed cloud)
考察云计算的一项重大发展:应用、平台、工具、安全性、管理和其他服务,正在从集中式数据中心模式物理上转变为在需求点分发和交付服务的模式。需求点可以扩展到客户数据中心,也可以一直扩展到边缘设备。
自主物件 (Autonomous things)
探索人类所处空间中物件的增强,通过各种层级的人工指导、自主和协作来增强感知、交互、移动和操纵空间的能力。
实用区块链 (Practical blockchain)
关注如何在未来三到五年内,利用区块链扩展企业的实用场景。
AI安全 (AI security)
解决以人为本的趋势背后的AI驱动的系统的现实安全性。
[空行]
[空行]
[空行]
趋势1:超自动化
(Hyperautomation)
[空行]
自动化是指,使用技术来促进或执行原本需要某种形式的人工判断或行动的任务。术语“任务(task)”不仅指执行、工作或操作环境中的任务和活动,还包括思考、发现和设计这些自动化本身的任务。
超自动化是指,用于交付工作的多种机器学习、套装软件和自动化工具的组合。倾向于使用何种类型的自动化,很大程度上取决于组织的现有IT架构和业务实践。超自动化不仅涉及工具平台的广度,而且涉及自动化本身的所有步骤(发现、分析、设计、自动化、测量、监视、重新评估)。
超自动化是一种无法避免的市场状态,因为组织必须快速识别和自动化所有可能的业务流程。它具有以下几点含义:
自动化范围更改 。
自动化的重点,现在涵盖了基于静态和严格规则的自动化单个离散任务和事务,以自动化越来越多的知识工作。反过来,自动化层级可以提供增强的动态体验和更好的业务成果。
一系列工具用于管理工作、协调资源 。
组织将越来越多地使用不断发展的技术集,以支持不断扩展的业务范围。这些工具包括任务和流程自动化、决策管理以及套装软件——所有这些都将包含越来越多的机器学习技术。
敏捷架构成为必需 。
这意味着组织需要具有重新配置操作和支持流程的能力,以响应不断变化的需求和市场中的竞争性威胁。高度自动化的未来状态只能通过敏捷的工作实践和工具来实现。
需要员工参与,重新定义员工创造价值的方式 。
如果不让员工参与运营的数字化转型,组织注定只能获得渐进式收益。这意味着,孤岛以及组织分配资源、整合合作伙伴和供应商能力的方式,是组织需要克服的挑战。
[空行]
超自动化需要选择合适的工具和技术来应对当前挑战。理解自动化机制的范围、它们之间的相互关系以及如何将它们组合和协调,是超自动化的主要重点。这很复杂,因为当前有许多多重重叠、但最终互补的技术,包括:
机器人流程自动化 (RPA, Robotic process automation):
RPA是一种将没有API的旧系统与更现代的系统连接的有用方法(请参见附注2)。它将比人更好地将结构化数据从系统A迁移到系统B,并解决了与传统系统的集成挑战。这些过程的范围通常是与移动数据相关的短暂任务。RPA工具还可以增强从事日常工作的知识工作者,消除日常工作和重复性任务。严格定义的集成脚本可构造和处理数据,将数据从一个环境移至另一个环境。由于集成基于与驱动现有应用屏幕的元数据进行交互的基础,因此业务最终用户通常更容易使用这些工具。
智能业务流程管理套件 (iBPMS, Intelligent business process management suites)。
除了RPA,iBPMS还管理长期运行的流程。智能业务流程管理套件是一组用于协调人、机器和物件的集成技术。iBPMS依靠流程和规则模型来驱动用户界面,并基于这些模型管理许多工作项的环境。与外部系统的集成通常是通过强大的API实现的。除了流程之外,强大的决策模型还可以简化环境,并为高级分析和机器学习提供自然的集成点。iBPMS软件支持业务流程和决策的整个生命周期:发现、分析、设计、实施、执行、监视和持续优化。iBPMS使公民开发人员(citizen developer,通常是业务分析人员)和专业开发人员能够在迭代开发以及流程和决策模型的改进方面进行协作。
RPA了解流程的方法是,记录日常工作中使用结构应用和数据库时,所操作的按钮和鼠标点击。然后,RPA工具模仿人类活动的活动和决策。RPA工具通常无法处理电子邮件和文本等非结构化数据。它们也很脆弱,基础应用的更改(如字段更改和按钮移动)就可以破坏脚本化流程。
[空行]
这些技术是高度互补的,并且Gartner越来越多地看到它们并行部署。
iBPMS平台可以编排复杂的工作风格,例如适应性用例管理或复杂事件驱动的流程[6] 。这一点变得越来越重要,尤其是在数字化流程的背景下,这些流程可以协调人员、流程和物联网中物件的行为。数字化时代快速变化的运营流程环境需要可操作的高级分析,以更智能地协调虚拟和物理世界中的业务流程。
关键是认识到组织正变得越来越受模型驱动,并且,能够管理这些模型的相互关联的性质和复杂版本控制是一项重要的能力。为了获得超自动化的全部好处,组织需要跨职能和流程孤岛的总体视图,开发越来越复杂的模型,类似于开发组织的数字孪生(DTO, digital twin of an organization)。
[空行]
[空行]
组织的数字化孪生形象地展示了职能、流程和关键绩效指标(KPI)之间的相互依存关系。DTO是用软件虚拟组织一部分的动态模型集。它依靠运营和/或其他数据,来了解并提供有关组织如何实现与其直接连接到当前状态和已部署资源的商业模式的持续智能。至关重要的是,DTO对预期客户价值交付方式的变化做出响应。
DTO从真人与机器协同工作的真实环境中汲取经验,以产生有关整个组织当前状况的连续智能。实际上,DTO为业务流程和决策模式提供了情境框架。它有助于捕获企业价值在何处链接到组织的不同部分,以及其业务流程如何影响价值创造。因此,DTO成为超自动化的重要元素。DTO允许用户对场景进行建模和探索,选择一个场景,然后在现实世界中予以实现[7] 。
[空行]
[空行]
包括机器学习和自然语言处理(NLP)在内的各种形式的AI技术,已迅速扩展了超自动化的可能性。它们通过增加在运行时快速解释人类语音、识别文档或数据中的模式和/或动态优化业务成果的功能,极大地改变了自动化的可能性范围。确实,当与RPA和iBPMS相关的产品结合使用时,它们开始影响许多行业,并使曾被视为知识工作者专有领域的产品实现自动化。但是,人工智能技术并没有取代这些工作者,而是在增强其创造价值的能力。随着供应商试图相互超越,这些AI技术已经引发了一场小型“军备竞赛”。人工智能技术具有:
在大多数RPA工具中改进的机器视觉功能 。
机器学习确实通过计算机视觉使RPA迈出了重要一步。例如,它可以识别“提交”按钮,并以虚拟方式按下它,而不管它出现在屏幕上什么位置。它已扩展为识别屏幕上的所有文本,就像光学字符识别(OCR)一样。进一步地,出现了可以将图像上的标签与动态填充的文本字段分开的工具。然后,这一创新使RPA工具能够与基于图像的界面进行交互,就好像它们是直接访问的应用一样。
优化的业务KPI 。
iBPMS或RPA工具,可以直接从短期任务或运行时间更长的业务流程中轻松调用机器学习模型或NLP功能。越来越多地将机器学习和NLP直接集成到具有预集成功能的iBPMS工具中,从而更轻松地进行关联的数据科学(即插即用机器学习)或从云供应商巨头(如亚马逊、Google、IBM和微软)调用外部服务。
出现在众多邻近和支持性技术中 。
这些技术包括能解释手写内容的高级OCR和智能字符识别(ICR)。随着客户直接与聊天机器人和虚拟个人助理(VPA)进行交互,NLP正在实现越来越多的自助服务自动化。
自动化过程发现 。
机器学习使供应商能够发现工作实践及其在工作场所中的不同变化。任务挖掘工具有时称为“流程发现”,可帮助组织深入了解其任务流,以获取任务步骤或活动的微观视图,然后可以通过RPA或iBPMS对其进行自动化[8] 。
智能字符识别(ICR, intelligent character recognition)是一种先进的光学字符识别(OCR),或更确切地说是手写识别系统,它让计算机在处理过程中学习字体和不同样式的笔迹,能提高准确性和识别水平。大多数ICR软件都有神经网络自学习系统,会自动为新的手写模式更新识别数据库。ICR扩展了扫描设备在文档处理方面的实用性, 从打印字符识别到手写体识别。某些情况下,ICR准确性可能不是很好,但在以结构形式阅读手写内容时可以达到97%以上的准确性。
智能虚拟助理(IVA, intelligent virtual assistant),或智能个人助理(IPA, intelligent personal assistant)或虚拟个人助理(VPA, virtual personal assistant),是一种软件代理程序,可以基于命令或问题为个人执行任务或提供服务。有时,聊天机器人(chatbot)一词用于指代提供在线聊天的虚拟助手,有时仅用于娱乐目的。一些虚拟助理能够解释人的语音,并通过合成语音做出响应。用户可以向虚拟助理提问,通过语音控制家庭自动化设备和媒体播放,并使用口头命令管理其他基本任务,如电子邮件、待办事项列表和日历。虚拟助理的功能和使用正在迅速扩展,苹果、Google、微软和亚马逊是最主要的供应商。
[空行]
RPA和iBPMS工具中增加了机器学习和NLP功能,通过将这些交互直接连接到自动化的后台运营和供应商生态系统,可以实现数字化客户和员工体验的产业化。此外,这可以实现一种背景相关的、情境自适应的方法,其中参与者之间的交互设置和顺序根据企业、合作伙伴和客户的目标以及实时不断更新和分析的运营智能来唯一地编排。iBPMS可以在支持客户和员工旅程的快速转变和/或改善的同时,主动执行大规模化背景相关的交互。此外,人工智能支持iBPMS自动化和编排可在运行时自行成形的业务流程。因此,这些过程可以被认为是自适应的、智能的,能执行最佳的下一个动作,而不是相同的可重复动作序列。
[空行]
“Navigate Optimal Routes for Process Automation With RPA, iBPMS and iPaaS”
“Market Guide for Technologies Supporting a DTO”
“Develop 3 Levels of Service for Your Center of Expertise to Scale DigitalOps and Robotic Process Automation”
“Artificial Intelligence Trends: Process Augmentation”
“The State of RPA Implementation”
“Best Practices for Robotic Process Automation Success”
“Create a Digital Twin of Your Organization to Optimize Your Digital Transformation Program”
“Comparing Digital Process Automation Technologies Including RPA, BPM and Low-Code”
[空行]
[空行]
[空行]
[空行]
趋势2:多元体验
(Multiexperience)
[空行]
到2028年,用户体验将在用户如何看待数字世界、如何与数字世界互动方面将发生重大变化。对话平台正在改变人们与数字世界互动的方式。虚拟现实(VR)、增强现实(AR)和混合现实(MR)正在改变人们感知数字世界的方式。感知模型和交互模型的组合转变,带来了未来的多感官、多触点体验。
这些模型将从具有技术素养的人类,转变为具有人类素养的技术。翻译的负担将从用户转移到计算机。
与用户的多种人类感官进行交流的能力,将为传递细微差别的信息提供更丰富的环境。
多元体验世界中的“计算机”,是用户周围的环境,包括许多接触点和感官输入。体验的多触点方面将跨联系人的各种边缘设备,包括传统的计算设备、可穿戴设备、汽车、环境传感器和消费电器[9] 。体验的多感官方面将使用所有人类感官,以及海洋般丰富设备的高级计算机感官(如热度、湿度和雷达)。将来,随着人类居住空间成为多感官、多触点的界面,“计算机”这一概念似乎显得古朴而过时。
多元体验的长期表现也称为环境体验 (ambient experience)。但是,这只会在2029年以后缓慢发生。尤其是隐私问题可能会削弱采用的热情和影响。在技术方面,许多消费类设备的生命周期长、许多设备独立开发的复杂性,将成为无缝集成的巨大障碍。不要期望设备、应用和服务会自动即插即用。相反,在不久的将来将出现设备专有的生态系统。
专注于特定场景的沉浸式体验和对话平台的专门用途,将于2024年得到长足发展。这些体验和平台将相互重叠,并整合在各种设备场景中,提供全系列感官输入/输出渠道。这可能是特定设备上针对性的体验,但是在多设备和感官渠道上支持更强大场景、支持特定环境(如制造工厂的环境体验)的机会将会增加。利用不断发展的多元体验开发平台对这些专门解决方案进行补充,平台包含更多的感官渠道和更多的设备目标,将远远超出更加传统的开发平台的Web和移动目标。
[空行]
[空行]
AR、VR、MR、多渠道人机界面(HMI, multichannel human-machine interface)和传感技术等各种技术和软件工具,均可用于构建沉浸式体验。沉浸式体验与其他体验方法的不同之处在于,它能够模拟现实的场景和环境,可以为用户提供可视化、可操作的信息,以练习操作、与虚拟人物进行交互。这些体验包括从智能手机上的简单AR到虚拟现实环境的完全沉浸体验等范围广泛的沉浸式体验。
VR提供了围绕用户的3D环境,并以自然的方式响应个体的行为。这可能是通过浸入式头戴式显示器(HMD)来遮挡用户的整个视野。HMD通过融合数字与物理因素来丰富沉浸式体验。但是当前的产品有很多局限,例如高功耗、笨拙的设计、笨拙的UI、延迟和有限的视野。
智能手机也可以成为移动VR和AR的有效平台。通过配件可以将智能手机变成HMD。但是HMD配置对于体验AR并不是关键,因为AR可以将数字叠加层整合到真实视频体验中。智能手机的屏幕变成一个“魔术窗口”,显示覆盖在现实世界之上的图形。 AR将背景信息叠加在一起,将增强的数据混合在现实世界对象的顶部(例如隐藏的线条叠加在墙壁的图像上)。尽管与基于HMD的方法相比,此方法具有局限性,但它代表了AR的广泛使用,易于使用、具有成本效益的切入点。
体验的视觉方面很重要,因为成像传感器可以捕获物理世界的特征,从而使系统可以将虚拟对象渲染并叠加到现实世界。但是,触摸(触觉反馈)和声音(空间音频)等其他感官模式也很重要,对于AR/MR来说尤其如此。在AR/MR中,用户可以与数字和现实世界的对象进行交互,同时保持在物理世界。手势和姿势识别可提供手和身体的跟踪,并且可以合并触敏反馈。新兴的AR云将通过提供现实世界的标准化空间地图,使AR/VR/MR体验的整合更加丰富[10] 。
尽管VR、AR和MR的潜力令人印象深刻,但仍然存在许多挑战和障碍。需要确定关键目标用户、探索目标场景。例如,对于在家、在汽车中、在工作中或与客户在一起等不同场景下的用户,探索目标用户的需求和业务价值。到2022年,将有70%的企业尝试使用沉浸式技术供消费者和企业使用,而25%的企业已将其部署到生产中。三个用例显示出明确的价值[11] :
产品设计和可视化 。
这可以是面向内部或面向外部的用例。沉浸式体验技术使设计师和客户可以虚拟地概念化、设计、探索和评估产品,而无需物理原型,同时考虑了用户的约束和环境。这种用法可改善团队之间的研发协作,缩短产品开发周期,并通过仿真改善产品设计。该用例在房地产和汽车开发中很普遍,尽管它可以应用于各种产品。
现场服务和操作 。
这是一个基于AR/MR的远程用例。沉浸式体验技术支持一线工人在现场完成任务,并提供提高效率的增强能力。迄今为止,该用例主要用于维护和维修,零件可视化和视觉指导。到2023年,三分之二的大型现场服务组织将为现场技术人员配备沉浸式应用,以提高效率和客户满意度,而2019年这一比例不到1%。
培训和模拟 。
这是一个面向内部的、基于VR的室内用例。它可以帮助员工学习新技能、提高现有技能[12] 。它可以提供更灵活、高效和自助式的培训,并为急救人员和其他面对前线的情况使用角色扮演培训。该用例包括针对关键任务的培训和高级操作技能。到2022年,培训和模拟行业中35%的大型企业将评估并采用沉浸式解决方案,而2019年这一比例不到1%。
[空行]
[空行]
对话平台能提供用户与机器交互的高级设计模式和执行引擎。与沉浸式体验一样,将添加其他输入/输出(I/O)机制,以利用视觉、味觉、气味和触觉进行多感官交互。已经发生的案例包括,Google和亚马逊都在智能音箱中添加了屏幕和摄像头。使用增强的感官渠道将支持各种能力,例如通过面部表情分析进行情感检测,通过分析来自加速度计的数据来识别健康状况的异常情况。但是到2023年,对这些其他感官渠道的使用仍将十分有限,基本都是个例。
会话平台已经达到引爆点:系统的实用性已经超过了使用难度。但是它们仍然不足。当用户需要了解UI可以理解的领域及这些领域的能力时,就会产生摩擦。对话平台面临的主要挑战是,用户必须以结构化方式进行交流。这通常是令人沮丧的经历。大多数对话平台不是在人与计算机之间进行健壮的双向对话,而是主要产生非常简单响应的单向查询或控制系统。随着供应商努力创建更自然的对话流程,这种情况开始改变。
随着时间的流逝,更多的对话平台将与不断增长的第三方服务生态系统集成,从而成倍地推动这些系统的实用性。对话平台之间的主要区别在于对话模式的健壮性以及用于访问、调用和编排第三方服务并提供复杂输出的API和事件模式。
[空行]
[空行]
多元体验开发平台(MXDP, multiexperience development platform)提供前端开发工具和后端服务,从而可以跨设备、模态和触点地快速、可扩展地开发无缝、有针对性的环境体验。设计时和运行时工具和服务通过统一的开发平台提供,且平台具有松散耦合的前端和后端体系结构。
MXDP不是“一次构建,随处运行”或“全渠道”解决方案。
MXDP的核心价值在于它能够合并一系列应用中的软件开发生命周期活动,以解决数字用户的旅程。对这种能力的需求只会随着应用、设备和交互方式数量的增加而增加。
提供优化体验的最佳实践是构建连接的、适合目的的应用,以使应用的设计、功能和能力与个体用户和方式保持一致。试图支持各类用户喜欢的所有功能的“一刀切”式应用体验是行不通的,必须创建“适合特定用途的”应用,着眼于用户达到目标的客户时刻或旅程步骤。这种方法有助于创建较小的专用应用,更易于设计、开发和部署。这种方法还可以使应用专注于用户在执行任务时喜欢的接触点,无论是在笔记本电脑上运行的Web应用、电话上的移动应用还是对话界面。
不需费力的体验,就是特定用户从一台设备移至另一台设备、或在环境体验中同时使用多个设备时具有一致的体验。多元体验设计要求后端足够灵活,能支持每个应用的不同功能和工作流程。由于用户并非总是使用相同的设备,经常在工作时从一台设备切换到另一台设备,因此后端必须提供连续的体验[13] 。
客户时刻 (customer moment)是指客户客户与公司之间的联系或互动(通过产品、销售人员或直接访问)时,客户有机会形成或更改对公司的印象。一般是指关键时刻(MOT, Moments of Truth),也就是品牌、产品或公司开展业务时有关客户体验的承诺。
通俗地说,客户时刻是客户“哇”的时刻,客户感到爽、受到赞赏的时刻。这是普通的客户体验和难忘的客户体验之间的区别。很明显,客户体验不是能够随机创建的,而是一系列公司与客户良好互动的自然产物。
全渠道 (omnichannel)是组织用于改善用户体验的跨渠道内容策略。也就是说,渠道经过整合和编排,让用户使用所有渠道进行互动时的体验效率更高、更令人愉悦。
Omnis是拉丁语,表示“每”、“所有”,因此omnichannel需集成所有的物理渠道(离线)和数字渠道(在线),提供统一的用户体验。也就是说,全渠道可以定义为:在联系渠道之内和之间发生的无缝、轻松、高质量的用户体验。
全渠道方法可在任何行业使用,早期案例主要在金融服务、医疗保健、政府、零售和电信行业。全渠道取代多渠道,并包括诸如地理位置、电子商务、移动应用和社交媒体之类的渠道。
[空行]
[空行]
“Market Guide for Conversational Platforms”
“3 Immersive Experience Use Cases That Provide Attractive Market Opportunities”
“Survey Analysis: Insights to Kick-Start an Enterprise Multiexperience Development Strategy”
“Critical Capabilities for Multiexperience Development Platforms”
“Magic Quadrant for Multiexperience Development Platforms”
“Architecting and Integrating Chatbots and Conversational Platforms”
“Market Guide for Augmented Reality”
“Architecture of Conversational Platforms”
[空行]
[空行]
[空行]
[空行]
趋势3:民主化
(Democratization)
[空行]
民主化的重点是,人们获取技术专长(如机器学习、应用开发)或业务专长(如销售流程、经济分析)时,大大简化人们的体验,而无需进行广泛而昂贵的培训。“公民访问”(如公民数据科学家、公民集成者)的概念以及公民开发和无代码模式的演变,就是民主化的例子。基于人工智能和决策模型的专家系统或虚拟助理的开发,是民主化的另一个重要方面[14] 。这些系统代表人们提供建议或采取行动,将他们的知识或专业扩展到自身的经验或训练之外。
公民访问 (citizen access):原意是政府设置某种方式(如网站上设置公民门户),为公民、企业和访客提供自由访问政府信息的公开服务。由于方式十分亲民,现也为一些企业(如银行)所使用。
公民开发人员 (citizen developer ):基于 公司或集体代码库、系统或结构创建新应用或程序的最终用户。一般而言,公民开发人员不是付费的专业开发人员,而是“业余用户”,他们在工作中使用可能工具来构建团队使用的应用。
也就是说,没 有特定编程资质和能力的公司员工,仍可作为公民开发人员参与公司内部应用或产品的开发。
云服务和代码抽象平台等新工具,已使公民开发人员可以进行“即时编程”,能够在没有特定要求的情况下创建新应用。这可能会导致“影子IT(shadow IT)”问题,即未获公司授权就可以进行开发,可能会影响已经存在的IT系统的完整性或组织性,例如数据库结构。所以,如果你支持这种未经批准的开发,必须先权衡风险与收益。
无代码开发 (No-code development):采用可视化的开发环境,让外行用户可以通过拖拉拽的方式,增加应用组件,创建完整的应用。使用无代码开发,用户无需事先具备编程知识,非技术业务用户可创建自己的应用。无代码开发具有增强敏捷性、降低成本、提高生产力等优点,但也存在安全威胁、影子IT等问题。
低代码 (Low-code)与无代码类似,但它要求开发人员具备一定的编程知识,他们可以在平台的约束下工作简化开发流程、提供用户体验等方面的更大灵活性。
[空行]
必须注意,民主化趋势的目标可能是企业内外部的任何人,包括客户、业务合作伙伴、公司高管、销售人员、装配线工人、专业应用开发人员和IT运营专业人员。从2020年到2023年,民主化趋势有四个关键领域正在加速发展:
应用开发的民主化 。
AI PaaS提供对复杂AI工具的访问,以便利用定制开发的应用。这些解决方案提供了AI模型构建工具、API和相关中间件,以构建/训练、部署和使用预建在IaaS上的机器学习模型。这可以涵盖视觉、语音以及任何类型的常规数据分类和预测模型。
数据和分析的民主化 。
构建AI驱动的解决方案的工具,正在从针对数据科学家的工具(AI基础设施、AI框架和AI平台)扩展到针对专业开发人员社区(AI平台和AI服务)和公民数据科学家的工具。这包括生成综合训练数据的工具,有助于解决机器学习模型开发的重大障碍[15] 。
设计的民主化 。
此外,用于构建AI驱动的解决方案的低代码应用开发平台工具,本身也具有AI驱动的功能,可协助专业开发人员、并使与AI增强解决方案的开发任务自动化。这可以扩展到附加应用开发功能自动化的低代码、无代码现象,能够增强公民开发人员的能力。
专业知识的民主化 。
非IT专业人员越来越多地使用强大的工具和专家系统,使他们能够利用和应用超出自身专业知识和培训的专门技能。在这种用户主导的环境中处理“影子AI”问题将是一大挑战。
[空行]
[空行]
市场正在迅速改变。从前,专业数据科学家必须与应用开发人员合作,才能创建大多数AI增强型解决方案;未来,专业开发人员可以使用作为服务交付的预定义模型单独运行。这为开发人员提供了AI模型生态系统,以及旨在将AI能力和模型集成到解决方案中的易配置 开发工具。
某些AI PaaS服务是完整的模型,开发人员可以简单地将其作为函数调用,传递适当的参数和数据即可获得结果。其他人可能会接受高级培训,但需要一些其他数据来定制模型。例如,可以对模型进行预训练来进行图像识别,但是需要训练数据集才能识别特定的图像。这些经过部分训练的模型的优点在于,它们需要更小的相关企业数据的数据集进行精细训练。
AI平台和AI服务套件的发展,不仅使广大开发人员能够提供AI增强型解决方案,而且还可以让开发人员的生产力更高。
这减少了AI项目的开发生命周期中的浪费和效率低下。可以通过API调用或事件触发器,访问预训练的模型。
应用团队必须确定要使用哪种外部提供商的AI服务。接下来,必须定义架构,让组织 的数据科学团队掌握开发定制领域和公司特定AI服务的方法,作为AI服务生态系统的一部分。这将使云服务提供商的决策变得更加复杂,因为需要选择待构建的底层平台、框架和基础设施,并训练和部署AI模型。我们预计,不断增长的需求将导致自定义模型在多环境中部署时标准化。
[空行]
[空行]
低代码应用开发并非新事物,但是数字化颠覆的融合已产生大量工具,以满足对快速应用开发平台不断增长的需求。有许多供应商提供解决方案[16] ,涵盖简单表单到全栈应用平台的广泛范围。低代码开发产品属于开发工具范围,主要针对公民开发人员能够从事业务领域。到2024年,低代码应用开发将占应用开发活动的65%以上。同样,到2024年,75%的大型企业将至少使用四个低代码开发工具,以进行IT应用开发和公民开发计划。
各种应用开发和功能测试使用AI实现自动化,是民主化的另一层次。到2020年,将会出现简化开发和测试工作的AI辅助工具。到2022年,我们预计使用虚拟软件工程师来生成代码将更加主流。Google的AutoML就是增强分析使开发人员无需专业数据科学家参与、即可自动生成新模型的典型案例。到2022年,至少40%的应用开发新项目将在团队中包含人工智能合作开发人员。
最终,AI驱动的高度先进开发环境,将使应用的功能性非功能性需求都实现自动化,开创“公民应用开发人员”的新时代。
在这个新时代,非专业人员将能够使用AI驱动的工具来自动生成新的解决方案。我们期望AI驱动的系统将推动更高的灵活性。它们将使非专业人员能够快速创建更加动态、开放和复杂的解决方案。
[空行]
[空行]
增强分析使用ML与AI辅助的数据准备、洞见生成和洞见解释,使业务人员无需专业数据科学家的帮助,即可充当“公民数据科学家”探索和分析数据。它通过三种主要方式使分析和AI民主化:
增强的数据生成和准备 :
使用ML自动化来增强数据创建、数据剖析、数据质量、数据协调、数据建模、数据操纵、数据充实、数据目录和元数据开发。这也正在改变数据管理的各方面,包括自动化数据集成及数据库与数据湖管理。
增强分析, 作为数据分析和商业智能(BI)的一部分
使业务用户和公民数据科学家能够自动发现、可视化和描述相关发现,而无需构建模型或编写算法。这些发现可能包括相关性、异常、聚类、细分、异常值和预测。用户通过自动生成的可视化和对话界面来浏览数据。
增强分析使用ML来自动化数据科学和AI建模的各方面 :
例如特征工程、用于模型选择的自动化机器学习(autoML)、模型可操作性、模型说明以及最终的模型调整和管理。这减少了对生成、操作和管理模型的专业技能的需求。
组织可以使用公民数据科学家、或经过半培训的业务专家,来填补数据科学和ML人才的缺口。到2021年,数据科学任务的自动化,将使公民数据科学家能够比专业数据科学家进行更多数量的高阶分析。Gartner预测,到2021年,增强分析将成为新购买分析和BI、数据科学和机器学习平台及嵌入式分析的主要驱动力。我们还预计,到2025年,数据科学家的稀缺,将不再阻碍组织采用数据科学和机器学习。组织越来越多地增加和外包数据科学工作。
增强分析也将成为嵌入与用户交互的自主物件中的分析的关键功能,尤其是使用对话界面的自主助理 。这种新兴的工作方式,使业务人员能够通过移动设备和个人助理,产生查询、浏览数据,并以自然语言(语音或文本)接收洞见,并采取行动。但是,这仅仅是增强分析在自主物件中的最初使用。增强分析功能可以将增强型数据科学功能嵌入任何类型的自主物件中。当自主物件需要分析才能运行时,它可以利用嵌入式增强分析功能进行响应。
在典型的分析场景中,人们通常会默认使用自己偏颇的假设,缺少关键发现,并得出不正确、不完整的结论。这可能会对决策和结果产生不利影响。增强分析使你可以探索更多假设、并识别隐藏模式。这也消除了个人偏见。但是,人工智能算法并非天生就没有偏见,因此必须注意不要通过有限的训练集而无意间引入新的偏见[17] 。
[空行]
[空行]
影子AI(Shadow AI)是民主化的自然结果。未经正式培训的个人就可以通过易于使用的工具,来开发AI驱动的解决方案,并通过类似的方式为他人提供对等的支持。就像“影子IT”一样,业务用户使用普通的技能,在BI工具上创建电子表格或分析模型,这使“影子AI”既有积极的一面、也有消极的一面。民主化为公民数据科学家、集成者和开发人员提供了新机会。业务用户可以使用越来越易用的工具,动态创建强大的AI驱动的模型和分析。这可能是提高生产力的财富,使企业能够更迅速地适应和驱动新商机,但将这些强大的工具开放给未经培训的受众也面临着挑战。
影子AI允许在IT所有权、控制权或管理权范围之外,让用户“带来自己的数据”、“带来自己的算法”,将“带来自己的”引入更细致的层次。只要有良好实践和培训,影子AI并非天然就是坏事。到2022年,将有30%使用AI进行决策的组织,将影子AI视为有效性和道德决策的最大风险。
[空行]
“Predicts 2019: The Democratization of AI”
“Low-Code Development Technologies Evaluation Guide”
“Four Real-World Case Studies: Implement Augmented DSML to Enable Expert and Citizen Data Scientists”
“Innovation Insight for AI-Augmented Development”
“Augmented Analytics Feature Definition Framework”
“Top 10 Data and Analytics Technology Trends That Will Change Your Business”
“How to Enable Self-Service Analytics”
“Predicts 2019: Democratization of IT Requires Different Strategies for Integration”
[空行]
[空行]
[空行]
[空行]
趋势4:人类增强
(Human Augmentation)
[空行]
人类增强是指使用科技来增强人类的能力。人类一直以科技来增强能力,甚至在引入计算机之前,打字机、复印机和印刷机等技术就增强了人类创建、复制和发布文本的能力。眼镜、助听器和假牙都是人类增强的历史示例。
计算机时代为人类增强增加了新的维度。文字处理、桌面发布、网页、博客和社交媒体,极大地扩展了我们创建和发布文本的能力。随着来自计算机科学的物联网、人工智能、智能音箱和VR等新技术的兴起,以及来自生物科学的CRISPR[18] 等技术的兴起,为人类增强创造了全新的机遇。
CRISPR(Clustered Regularly Interspaced Short Palindromic Repeats)是原核生物基因组内的一段重复序列,是生命进化历史上细菌和病毒斗争产生的免疫武器。简单说,这就是病毒把自己的基因整合到细菌,利用细菌的细胞服务于自己的基因复制,而细菌为了将病毒的外来基因清除,进化出CRISPR-Cas9系统,细菌利用它可以把病毒基因从自己的基因组上切除,这是细菌特有的免疫系统。
微生物学家掌握了细菌拥有多种切除外来病毒基因的免疫功能。比较典型的模式是,依靠一个复合物、在一段RNA指导下定向寻找目标DNA序列,然后将该序列进行切除。许多细菌免疫复合物都很复杂,科学家掌握了对一种蛋白Cas9的操作技术,并先后对多种目标细胞DNA进行切除。这种技术即被称为CRISPR/Cas9基因编辑系统,具有非常精准、廉价、易于使用,并且非常强大的特点。据预测,这种基因编辑技术将改变我们的星球、改变我们生活的社会和周围的生物。
[空行]
人类增强探索如何使用技术来提供认知和身体改善,并将其作为人类体验的组成部分。计算机和应用不是人类正常体验之外的东西,它们已经成为人类日常体验中自然的、有时是必要的一部分。此外,人类增强还包括生物工程因素,而不局限于计算机和应用的开发。在一定程度上, 我们早已踏上了这条道路。对于许多人来说,智能手机是必不可少的工具,并且是永恒的伴侣。社交网络和电子邮件之类的电子连接,已成为人们之间的主要链接。自从计算机问世以来,药物就一直在增强人类的生命。人类增强是组合创新的典范,它汇集了许多趋势,包括:
[空行]
[空行]
人类增强影响我们在物理和数字空间中的移动、感知和交互方式,以及我们处理、分析和存储信息的方式。增强可以大致分为身体和认知两大类,尽管它们之间的界限会随着时间而模糊。
身体增强强化人类能力的方式是,在人体中植入或放置技术元素,改变人类固有的身体能力。汽车、采矿、石油和天然气以及其他行业,正在使用可穿戴设备来提高工人的安全性。可穿戴设备还能提高零售、旅行和医疗保健等行业的工作场所生产力。身体增强还包括使用生物学或其他手段来改变人体。在某些情况下,身体增强代替了个人已经丧失的人类能力(如假肢);但在某些情况下,这些替代功能可能会超过人类的自然能力。可以从许多方面考虑身体增强:
感官增强 :
听力、视力和其他增强设备或植入物,可以改善知觉。虚拟、增强和混合现实是感官增强的当前示例。在新兴技术领域,多家公司正在尝试使用智能隐形眼镜来检测眼泪和眼压中的葡萄糖水平[19] 。研究人员还在尝试开发一种模仿人鼻的“电子鼻”[20] 。
附属肢体和生物功能增强 :
使用外骨骼和假肢替换或增强能力,是人类增强的扩展领域。眼外科手术增强在职业高尔夫球手中很普遍[21] 。人工耳蜗可以代替无功能的听觉神经,并且已经采用类似的技术来复制眼睛。美容行业在使用被动植入物改善指甲、头发、眼睛和身体部位的形状方面处于领先地位。可以说,制药业多年来一直在增强人类的生物学功能。促智药是指可以改善心理技能的天然或合成物质,尽管在针对特定医学状况的治疗以外使用此类物质引起很大争议。
大脑增强 :
目前正在使用迷走神经刺激器等植入物来治疗癫痫发作[22] 。正在探索各种用途的脑植入物,包括记忆存储[23] 和用于解码神经模式和合成语音的脑植入物[24] 。Neuralink试图开发脑植入物 ,将人脑连接到计算机网络[25] 。
Neuralink是由马斯克(Elon Musk)等人创立的神经技术公司,致力于开发植入式脑机接口(BMI)。公司成立于2016年,总部位于旧金山。自成立以来,公司已聘请了来自各大学的多位知名神经科学家。
Neuralink正在开发一种类似“缝纫机”的设备,能够将非常细(宽度为4至6μm)的线植入大脑,预计将在2020年进行人体实验。
Neuralink短期目标是 制造可治疗严重脑部疾病的设备,最终目标是增强人类能力,有时也称为超人类主义。
[空行]
认知是人类通过感官输入、生活经验、学习以及对输入、经验和教育的思考而获得知识的过程。认知技能用于理解、处理、记住和应用信息以做出决定和采取行动。认知增强可以增强人们思考和做出更好决策的能力。认知增强可以通过访问信息、利用传统计算机系统上的应用及智能空间中新兴的多元体验界面来实现。这包括增强智能场景,其中人类和人工智能共同努力来提高决策和学习等 认知效能。另外还包括,增强人类感官或大脑能力的身体增强,注入给认知增强新模型的能力,例如使用智能药物和脑植入物来存储记忆[23] 。
可穿戴设备是如今身体增强的一个示例。随着可穿戴设备日益成熟、使用率日益提高,消费者和员工将开始寻求其他身体增强的能力,以改善个人生活(即健康和健身)、或更有效地完成工作(即外骨骼和植入物)。在接下来的十年中,随着个体寻求个人能力强化,身体增强、认知增强等人类增强的水平将越来越普遍。反过来,这将创建一种新的“消费化”效果,员工试图利用强化和扩展个人能力,以改善办公环境。到2023年,30%的IT组织将通过“自带增强功能”(BYOE)扩展BYOD策略,以应对员工队伍中的增强人群。
BYOD (Bring Your Own Device),是指员工将个人设备用于工作目的,包括个人电脑、手机、平板等。BYOD是必然趋势,如果条件不允许,公司也可以利用部分 BYOD趋势,如 BYOC(自带电脑)。
此处的BYOE (Bring Your Own Enhancement)作为BYOD的延伸,尚未成为公认概念。BYOE亦指Bring Your Own Encryption、Bring Your Own Equipment等,与此处含义不同。
[空行]
[空行]
人类增强将是人与人之间、人与周围智能空间之间互动的主要手段。业务领导者和IT领导者应该计划组织如何采用、利用和适应即将发生的变化。随着消费者和员工将更多生活整合到可以增强智能的人类增强功能中,组织将不得不解决数据透明性,隐私和自治的问题[27] 。
在选择人类增强技术和方法时,企业必须检查五个主要领域:
安全性 。
人类增强技术必须实现并维持安全风险,保持在已知且可接受的状态。安全风险将无处不在,攻击表面不再受限于特定的设备或物理位置,可能会与人体一起传播。
隐私权 。
人类增强提供了超级能力,可以访问有关增强人群的深入知识和数据。但数据必须受到保护。
合规性 。
政府和监管机构经常发布法规,并提出合规性要求,这使得合规性对全球企业极为复杂,尤其是因为各机构仍在努力掌握人类增强技术的含义。
健康影响 。
人体增强可能会带来暂时无法理解的长期精神和身体影响。
伦 理 。
实施人类增强的技术和过程,带来了严重的伦理问题。这包括道德考量和评估,以确定特定的漏洞、风险和道德问题。例如,富裕人士可以增强自己和子女,而欠富裕人群则无法增强,数字鸿沟会扩大吗?回答这些社会问题将变得越来越重要。
各种类型和规模的企业都在考虑通过人类增强,来达成不同时间范围的多个业务的各种成果。因此,当他们有意开始利用人类增强探索提升人们的能力时,必须考虑人类实验的教训、建议和原则。企业应该在预防原则和积极原则 两个经典的道德原则之间取得平衡,Gartner将其修正为“谨慎原则”:
预防原则 :
如果一项行动或政策可能对公众或环境造成严重或不可逆转的损害,那么在没有科学的共识认为不会造成损害的情况下,举证责任将由那些采取行动的人承担[28] 。
积极原则 :
此原则由马克斯·莫尔(Max More)提出,是“超人类主义”运动的主要宗旨。在实施限制性措施时,它提出了一些必要条件:“根据现有科学评估风险和机遇,而不受制于普遍的看法 。既要考虑限制本身的成本,也要考虑放弃机会的成本。积极考量与可能性和影响严重程度成比例的因素,以及具有较高期望值的因素。保护人们的实验、创新和进步的自由。”[29]
谨慎原则 :
在预防原则和积极原则之间取得平衡。它建议组织继续创新,但创新的方式应不会对个人、公司或整个环境造成风险。
超人类主义 (transhumanism, 缩写为H+或h+)是一项国际哲学运动,倡导通过开发和提供广泛可用的先进技术,来极大地提高人类智力和生理机能,从而改变人类的状况。
超人类主义的思想家研究了新兴技术的潜在利益和危险,这些技术可以克服人类的基本限制以及使用此类技术的伦理限制。最常见的超人类主义论点是,人类最终可能会依靠自己的能力从当前状况极大地扩展为具有后人类标签的能力,从而将自己转变为不同的存在。
受科幻小说的开创性影响,超人类主义对转变后的人类的愿景吸引了包括哲学和宗教在内的广泛支持者和反对者。
[空行]
[空行]
“Maverick* Research: Architecting Humans for Digital Transformation”
“Emerging Technology Analysis: Smart Wearables”
“Technology Investments for Frontline Workers Will Drive Real Business Benefits”
“Hype Cycle for Emerging Technologies, 2019”
“Market Insight: Increase User Engagement for Voice-Enabled Virtual Assistants Through a More Targeted User Experience
[空行]
[空行]
[空行]
[空行]
趋势5:透明度和可追溯性
(Transparency and Traceability)
[空行]
数字道德和隐私越来越受到个人、组织和政府的关注。消费者越来越意识到他们的个人信息很有价值,并且需要控制。组织意识到保护和管理个人数据的风险在不断增加,政府正在实施严格的立法,确保企业保护好个人数据。
人工智能和使用ML模型做出自主决策引起了新的关注,数字道德让人们认识到,AI应该是可解释的,必须保证AI系统以道德和公平的方式运行。透明度和可追溯性是支持数字道德和隐私需求的关键要素。
透明度和可追溯性不是单一产品或单一行动。它指的是解决法规要求、体现使用AI和其他先进技术的合乎道德的方法、修复对公司日益缺乏的信任的一系列态度、行动以及支持性技术与实践。
透明度和可追溯性要求关注信任的六个关键要素:
道德 :
组织是否在使用个人数据、算法和系统设计方面具有强大的道德原则,而这些原则超出了法规范围,并且对所有相关方都透明?
完整性 :
组织在设计系统时,是否确保减少或消除偏见,不会滥用个人数据?
开放性 :
道德原则和隐私权承诺是否清晰,且易于获取?此类政策的变更,在决策过程中是否引入普通人的参与?
问责制 :
是否有测试、保证和审核的机制,确保可以识别和解决隐私或道德问题?这不仅适用于遵守法规要求,而且适用于未来技术带来的新的道德或隐私问题。
能力 :
组织是否实施了设计原则、流程、测试和培训,以使有关人员对组织能够兑现承诺感到满意?
一致性 :
策略和流程是否得到一致处理?
[空行]
[空行]
算法决策驱动着组织和消费者的许多工作:招募、购买产品和服务、在网上看到的内容、接受或拒绝贷款,甚至入狱[30] 。算法有偏差或不正确,会导致不良的业务决策,并有可能遭到员工、投资者和客户的严重反对, 甚至可能造成严重伤害,造成公司面临刑事处罚。法律风险包括性别和种族偏见,以及其他形式的歧视性活动。缺乏解释性或无法证明缺乏偏见,意味着商业活动无法在公开场合或法庭上辩解。
不透明算法(如深度神经网络)将许多隐含的、高度可变的交互作用合并到预测中,这可能很难解释。人工智能偏见引起了人们对问责制和公平性的担忧。因此,AI社区和企业领导者应监测和解释可能危害社会和企业的偏见的后果。例如,人工智能偏见会导致政治观点的两极分化、不信任信念的持续存在以及业务时点之间的虚假关联。
深度神经网络 (DNN, deep neural network)是具有一定复杂度、两层以上的神经网络。深度神经网络使用复杂的数学建模进行数据处理。
一般来说,神经网络是一种模拟人脑活动的技术。深度神经网络定义为具有输入层、输出层和至少一个隐藏层的网络,每层在一个过程中执行特定类型的排序。
术语“深度学习”也用于描述深度神经网络,因为深度学习代表一种特定形式的机器学习,使用人工智能方面的技术,试图以超越简单输入/输出协议的方式对信息进行分类和排序。
[空行]
可解释AI是描述模型、突出其优缺点、预测可能的行为、识别潜在偏见的一组能力。它可以阐明描述性、预测性或规范性模型的决策,以确保算法决策的准确性、公平性、责任性、稳定性和透明性。可解释AI为支持AI治理提供了技术基础。AI治理是指为应用人工智能、预测模型和算法分配和确保组织责任、决策权、风险、政策和投资决策的过程。
具有可解释AI功能的增强分析解决方案,不仅向数据科学家显示模型的输入和输出,而且还在解释系统为何选择特定模型、增强数据科学和ML应用了哪些技术。如果没有可接受的解释,自动生成的见解和模型、充满AI偏见的黑匣子可能引起人们对法规、声誉、问责制和公平性的担忧,并导致对AI解决方案的不信任。
透明度和可追溯性不仅是企业自身需要接受的,也是组织评估在采购使用AI的应用和服务时越来越重要的考量要素。到2025年,政府和大型企业采购使用AI的数字产品和服务的合同中,将有30%需要采用可解释且符合道德的AI。
[空行]
[空行]
人们越来越担心公共和私营部门的组织如何使用其个人信息;没有主动解决这些问题的组织 只会增加人们的激烈反应。
私营部门越来越受到隐私法规的约束,执法和安全部门受到的控制却少得多。警察部门使用面部识别,来定位他们感兴趣的人。他们使用自动车牌识别(ANPR)来跟踪感兴趣的车辆。他们还使用健身追踪器的数据来确定犯罪时人们的位置和心率[31] 。他们甚至使用Face ID来解锁犯罪嫌疑人的手机[32] 。执法部门通过数十亿个端点收集信息,可以识别出你是谁、你在哪里、你在做什么,甚至你在想什么。
关于隐私的任何讨论,都必须基于更广泛的数字道德主题及客户、选民和员工的信任。尽管隐私权和安全性是建立信任的基础,但信任包含的内容实际上更广泛。
根据牛津词典的定义,信任是对某人或某物的可靠性、真实性或能力的坚定信念。信任通常被视为接受陈述的事实,而无需证据或调查。但实际上,信任通常是随着时间的推移从可证明的行动中获得,而不是盲目提供。
最终,组织在隐私方面的立场,必须受制于它在道德和信任方面的广泛立场和行动。从隐私到道德,意味着对话的范围从“我们符合要求吗?”转向“我们是否在做正确的事情?”、“我们是否表明我们正在努力做正确的事情?”。从合规性驱动的组织转为道德驱动的组织,可以形容为意向的升级[33] 。
人们有理由担心个人数据的滥用,并开始反击。错误的个性化尝试、媒体报道和诉讼已经向客户清楚地表明:他们的数据很有价值。因此,他们想要收回控制权。客户可以选择退出服务、以现金或比特币付款、使用VPN掩盖位置、提供虚假信息或简单地退出关系。
在欧洲、南非、韩国和中国等许多司法管辖区,“ 被遗忘权”已被立法。数据可移植性,使客户能够更轻松地将个人数据和业务转移到其他地方。组织花费十余年有效利用、且极有价值的个人信息正在消失。未将隐私纳入个性化策略可能会带来不良结果,例如客户流失、缺乏忠诚度和不信任感、以及品牌声誉受损。在某些情况下,如果客户感到隐私受到威胁,监管部分甚至可能会干预。
被遗忘权 (RTBF, Right to be forgotten)是有关从互联网搜索和其他目录中删除个人负面私人信息的权利。此概念已在欧盟和阿根廷进行了讨论并付诸实践。这个问题源于个人的愿望,即“以自主方式确定自己的生活发展,而不会因过去采取的特定行动而永久或定期受到污名化”。
[空行]
滥用个人数据的公司将失去客户的信任。诚信是驱动收入和盈利能力的关键因素。在组织中建立客户信任是困难的,失去信任却很容易。但是,获得并保持客户信任的组织将蓬勃发展。我们预计,拥有数字化信誉的公司将比没有信誉的公司产生更多的在线利润。但是,并非所有的透明度和信任元素都可以轻松实现自动化。需要提供更多的人力来提供责任、问题的联系点,并在出现问题时进行纠正。
[空行]
[空行]
欧盟通用数据保护条例(GDPR, The EU’s General Data Protection Regulation)重新定义了隐私的基本规则,并且已对全球产生影响。它最高可以处罚全球年收入的4%或2000万欧元的罚款。我们预计,到2021年年底之前,将对GDPR违规行为实施超过10亿欧元的制裁。许多其他国家和地区正在制定或实施隐私法规,而全球范围内不断发展完善的隐私法规将继续以与客户、公民和员工互动的方式向组织发起挑战。
立法还推动了中国、俄罗斯、德国和韩等司法管辖区的数据驻留问题。组织必须评估运营所在国家/地区的数据驻留要求,以确定数据驻留策略。本地数据中心是一种选择,但通常很昂贵;并且在许多情况下,存在跨境安全传输个人数据的法律和逻辑控制。云服务提供商正在将数据驻留地点,设置在数据驻留受到法律保护或客户偏好驱动的国家。
可解释且符合道德的AI正在成为一个政治和法规问题。英国政府数据道德和创新中心新已经开始对金融服务行业的算法偏差进行审查。美国政治家也在提出法规。
贯彻“设计隐私”原则,你的产品和服务将比竞争对手的产品和服务更具隐私友好性。这创建了基于信任的价值主张。 2017年的一项调查表明,87%的消费者表示,如果不相信公司会负责任地处理数据,他们会将自己的业务转移到其他地方34] 。IEEE标准协会等 其他标准组织,已经建立了针对AI和自主系统中的道德考量以及个人数据和AI代理的标准的一系列标准[35] 。企业应跟踪这些原则的发展,并在需要时采用它们,以彰显道德、一致性和能力
[空行]
“Top 10 Data and Analytics Technology Trends That Will Change Your Business”
“Build Trust With Business Users by Moving Toward Explainable AI”
“Hype Cycle for Artificial Intelligence, 2019”
“Build AI-Specific Governance on Three Cornerstones: Trust, Transparency and Diversity”
“Modern Privacy Regulations Could Sever or Strengthen Your Ties With Customers”
“The CIO’s Guide to Digital Ethics: Leading Your Enterprise in a Digital Society”
“Use These Privacy Deliverables in Every IT Development Project”
“Build for Privacy”
“Hype Cycle for Privacy, 2019”
[空行]
[空行]
[空行]
[空行]
趋势6:赋权边缘
(The Empowered Edge)
[空行]
边缘计算描述这样的计算拓扑:信息处理以及内容收集与传递的位置更靠近信息的来源、存储库和使用者。边缘计算借鉴了分布式处理的概念,它尝试将流量和处理保持在本地,从而减少延迟、利用边缘的能力、在边缘实现更大的自主性。
目前人们关注边缘计算,大部分需求来自于物联网系统,它需要为制造业、零售业等特定行业向嵌入式物联网世界提供断开连接或分布的能力。但是,边缘计算将成为几乎所有行业和场景的主要因素,因为边缘将获得越来越先进和专业的计算资源及更多数据存储的支持。机器人、无人机、自动驾驶汽车和操作系统等越来越复杂的边缘设备,正在加速这一关注点的转移。
随着智能向端点、网关和类似设备的迁移,面向边缘的物联网架构正在不断发展。但是,今天的边缘架构仍存在层级结构,信息通过端点中定义明确的层流到近端、有时甚至到远端,最后是集中式云和企业系统。
赋权边缘 (Empowered edge)是云计算和大数据时代设备管理的关键概念,用于讨论计算的中心转向分布于网络边缘、最终用户和最终用户设备的能力。赋权也称为设备民主化。
赋授边缘的思想,是工程师和企业将越来越多的计算事务和数据传输置于日益复杂的网络节点系统的边缘。处理物联网的主要挑战之一是管理分散网络,而赋权边缘有助于实现安全和效率的目标。
赋权边缘还可以很好地配合云计算的原理。在云时代,数据不断被发送到不同的利益相关者或合作伙伴,将网络边缘作为完成业务的场所是有意义的。
[空行]
从长远来看,这些整齐的层级将分解为更加非结构化的架构,由范围广泛的“物件”和服务组成,并通过一组分布式云服务链接至动态灵活的网格中。在这种情况下,无人机等智能“物件”可能会与企业物联网平台、政府无人机跟踪服务、本地传感器和城市级本地云服务进行通信,然后与附近的无人机进行对等交换,以用于导航目的。
边缘、近边缘和远边缘连接到集中式数据中心和云服务。边缘计算解决了许多紧迫的问题,例如高带宽成本和不可接受的延迟。边缘计算拓扑将在不久的将来以独特的方式实现数字业务和IT解决方案的特定功能。
分布式云的演进将越来越多地提供一组通用或互补的服务,它们可以集中管理,但可以传送给边缘环境去执行。
网格架构将实现更灵活、智能和响应能力更强的点对点物联网系统,尽管通常以增加复杂性为代价。网格结构也是许多分布式网络生态系统的结果。向数字业务和产品的根本转变,必须利用智能网格架构来获得竞争优势。从集中到边缘、再到网格的演进,还将对产品开发以及不断发展的团队在云和边缘设计方面的技能产生重大影响。网格标准还不成熟,尽管IEEE和OpenFog联盟等组织正在网格架构领域付出努力。
端点数量不断增加、也越来越复杂,可以AI驱动、并能运行Linux等操作系统,因此网格架构将越来越流行。新的网格架构将给物联网系统带来极大的复杂性,并可能使设计、测试和支持等任务更具挑战性。此外,网格通常意味着更多的点对点活动,这将涉及合作伙伴和生态系统,而它们并不仅限于单个产品。
到2028年,我们预计在边缘设备中嵌入的传感器、存储、计算和高级AI能力将稳步增长。但是,边缘是一个异构概念,其范围从简单的传感器和嵌入式边缘设备,到移动电话等熟悉的边缘设备、以及自动驾驶汽车等高度复杂的边缘设备。在不同情况下使用的不同类型的边缘设备,可能具有非常不同的使用寿命,范围跨度达1~40年。这些因素,以及厂商将更多功能嵌入到边缘设备的迅速推动,构成了复杂而持续的管理与集成挑战。
智能将在各种端点设备上向边缘发展,包括:
简单的嵌入式边缘设备(如家电、工业设备)
边缘输入/输出设备(如音箱、屏幕)
边缘计算设备(如智能手机、PC)
复杂的嵌入式边缘设备(如汽车、发电机)
这些边缘系统将直接或通过中间边缘服务器或网关,与超大规模后端服务连接(请参阅附注3)。
边缘的复杂性继续增长。智能将在各种端点设备中向边缘发展。类别之间的边界将会模糊,例如:
简单的嵌入式边缘设备 。
此类设备包括开关、灯泡、工业设备、消费类电子产品和家用电器。许多此类现有设备可能仅具有简单的传感器和执行器。趋势是驱动更多的本地计算、存储及更高级的传感器。在消费市场上,这些简单的设备正在演变为更复杂的设备,包括可以用作家庭自动化系统集线器的智能恒温器,和以类似方式工作但更复杂的智能冰箱、本地计算/存储和显示技术。消费类设备的典型使用寿命为5至20年,而工业资产的使用寿命通常为40年。如此悠长的时间周期,创造了在已安装的基础上具有广泛能力的环境。
边缘I/O设备 。
此类设备包括扬声器、照相机和屏幕等设备。它包括简单的、以I/O为中心的设备,它们在很大程度上依赖于本地服务器和网关或外部云服务提供的能力。许多边缘I/O设备将具有更大的本地能力,尤其是用于AI和其他专门任务的嵌入式芯片等形式。我们期望它们的寿命为3~10年。
边缘计算设备 。
此类设备包括移动设备、笔记本电脑、PC、打印机和扫描仪。这些设备通常具有合理水平的计算和存储能力。在未来几年,它们将包括越来越多的传感器和更复杂的AI芯片。此类设备的典型使用寿命为1~5年,因此具有快速更新的最大潜力。这些设备通常将充当环境中其他边缘设备的本地处理或存储系统。
复杂的嵌入式边缘设备 。
此类设备包括汽车、拖拉机、轮船、无人机和机车。在现有的设备安装中,此类设备能力差异很大,但这些设备将逐渐成为“微型网络”。它们将具有广泛的传感器、计算、存储和嵌入式AI能力,并具有返回网关、服务器和基于云的服务的复杂通信机制。这类设备的寿命为3~20年、甚至更长。长周期使用以及新设备中高级能力的快速扩展,将让一组设备中的功能一致性变得很复杂。这将导致许多部门中提供“即服务”模式,以促进设备的更快更新。
空行]
[空行]
到2022年,数字化商业项目的结果,企业产生的数据将有75%在传统的集中式数据中心或云之外创建和处理,而今天这一比例还不到10%。迈向分布式数据的这一趋势,迫使组织在集中式数据采集和处理、以及在产生数据的地方进行本地化采集和处理之间进行不同的权衡。现代的业务场景要求数据管理功能向边缘移动,将处理带入数据,而不总是收集数据进行集中处理。但是分布式“连接”的范式,也带来了很多挑战。例如:
如果数据保留在边缘,那么将以什么形式存储?
如何在那里实施治理控制?
如何将其与其他数据集成?
为了应对这些挑战,数据和分析领导者需要采用更加现代的方式来描述、组织、集成、共享和管理数据资产。
尽管并非全部的数据管理都需要在边缘进行,但现代用例确实越来越多地将需求推向这个方向。现代的数字化业务应用具有高度分布式的本质,这包括:物联网解决方案的架构,挑战组织管理和处理大规模数据和复杂性的能力,而大多数组织是没有准备好的。这种向边缘计算转移的趋势,将产生以下影响[36] :
数据和分析用例及解决方案,需要支持新的分布式数据架构,而这已超出数据和分析领导者当前的数据管理能力。
在数据管理中涵盖分布式数据存储和处理,以确保可以在数据驻留的地方提供支持。
分布式数据需要分布式数据管理能力,要求数据和分析领导者重新平衡在边缘处理数据的能力。
通过基于云的数据存储、分布式并行处理平台和嵌入式数据库技术,来扩展数据持续保存的能力。
边缘计算和其他分布式环境将挑战数据管理技术厂商商的能力,数据和分析领导者需要更加仔细地审查他们如何掌控相关技术市场。
根据处理和治理分布式数据的能力来评估现有和潜在的供应商。
[空行]
[空行]
边缘设备彼此之间及后端服务之间的连接,是物联网和智能空间的推动者。5G是4G(包括LTE、LTE-A和LTE-A Pro等)之后的下一代蜂窝标准。国际电信联盟(ITU)、第三代合作伙伴计划(3GPP)和欧洲电信标准化协会(ETSI)等几个全球标准机构已经定义了5G标准,其后续迭代还将支持具有低功耗、低吞吐量要求的设备的窄带物联网。新的系统架构包括核心网络切片和边缘计算。
5G解决了关键技术通信的三个方面,每个方面都支持独特的新服务,并可能支持新的商业模式(如时延作为服务):
增强移动宽带(eMBB),大多数提供商可能会首先实施。
超可靠和低时延通信(URLLC),可解决许多现有需求,例如在工业、医疗、无人机和运输等领域,可靠性和延迟需求超过了带宽需求。
大规模机器类型通信(mMTC),可满足物联网边缘计算的规模需求。
使用更高的蜂窝频率和大容量,将需要非常密集的部署及更高的频率复用。因此,我们预计大多数公共5G部署最初的重点是孤岛式部署,而不是全国范围的连续覆盖。我们预计,到2020年,全球4%的移动网络通信服务提供商将推出5G商用网络。许多CSP不确定可能推动5G的用例和商业模式的性质。我们预计,到2022年,组织将主要使用5G来支持物联网通信、高清视频和固定无线访问。未经许可的无线电频谱的发布(美国的公民宽带无线电服务[CBRS],以及英国和德国的类似举措)将促进私有5G(和LTE)网络的部署。这将使企业能够利用5G技术的优势,而无需等待公共网络扩大覆盖范围。
应确定肯定需要边缘性能的5G高端性能、低延迟或更高密度的用例。将组织对此类用例的计划利用与提供商到2023年的预期部署进行对照。评估在特定的物联网用例中,可能实际上比5G更合适、更具成本效益的可用替代方案,示例包括低功耗广域网(LPWA),如基于4G LTE的NB-IoT或LTE Cat M1、LoRa、Sigfox和无线智能普适网络(Wi-SUN)。
5G的G,代表Generation,5G就是第5代无线网络。无线通信的目的是提供高质量的可靠通信,就像有线通信(光纤)一样,每一代服务都朝着这个方向迈出了一大步。
最早的商业蜂窝网络是上世纪70年代后期引入的,并在整个80年代建立了全面实施的标准。1987年,澳大利亚的Telecom(今天有Telstra)推出了使用1G 模拟系统的第一个蜂窝移动电话网络。1G是一种模拟技术,电话的电池寿命较短,语音质量差,没有太多的安全保护。1G的最大速度为2.4kbps。
从1G到2G ,获得了首次重大升级,2G网络使用了数字信号。这一代的主要动机是提供安全可靠的通信渠道,实现了CDMA和GSM的概念,提供了短信和彩信等数据服务。2G蜂窝电信网络由Radiolinja(现为Elisa Oyj的一部分)于1991年在芬兰推出GSM网络。2G的许多基本服务今天仍在使用,如SMS、内部漫游、电话会议、呼叫保持和基于服务的计费等。2G时代,GPRS的最高速度为64kbps。
3G 设定人们了解和喜爱的大多数无线技术标准,引入了网络浏览、电子邮件、视频下载、图片共享和其他智能手机技术。3G于2001年投入商业应用,目标是促进更大的语音和数据容量,支持更广泛的应用以及以更低的成本增加数据传输 。3G标准利用UMTS作为核心网络体系结构,基于移动设备和移动电信使用的服务和网络形成一组标准,并符合国际电信联盟的国际移动电信2000 (IMT-2000)规范。在3G中,跨不同设备类型(电话,PDA等)的通用访问和可移植性成为可能。3G通过改善通话中音频的压缩方式来提高频谱效率 ,因此在同一频率范围内可以同时进行更多通话。IMT-2000标准要求3G的固定速度为2Mbps、移动速度为384kbps。
与3G相比,4G 技术非常不同,其目的是为用户提供高速、高质量和高容量,同时提高安全性,并降低IP上的语音和数据服务、多媒体和互联网的成本。广泛部署的主要4G标准是 LTE,它是对现有UMTS技术的一系列升级。当设备移动时,4G网络的最大速度为100Mbps或1Gbps;用于静止或步行等低移动性通信时,延迟从大约300ms减少到小于100ms,并且大大降低了拥塞。
5G 是目前正在开发的第五代无线技术 ,有望显着提高数据传输速度,提高连接密度,降低等待时间,并带来其他改进。5G是类似于GSM (2G)、CDMA (3G) 和 LTE/LTE-A (4G)的蜂窝无线技术,可在各种许可和非许可频段中运行,例如低于1GHz、低于6GHz和高于6GHz。5G网络运营商认为,5G应在下行链路上支持20Gbps,在上行链路上支持10Gbps。
eMBB,mMTC和URLLC是5G技术支持的不同用例。
eMBB:增强型移动宽带。峰值数据速率10至20Gbps,必要时为100Mbps。流量增加10000倍,支持500Kmph的高移动性,可节省100倍的网络能源。
mMTC:大规模机器类型通信。支持高密度设备,支持远距离,支持低数据速率(大约1~100Kbps)。可利用M2M的超低成本优势,并能提供10年的电池寿命。
URLLC:超可靠和低延迟通信。提供超快速响应的连接和少于1毫秒的空中接口延迟。在移动设备5G基站之间提供5毫秒的端到端延迟。超可靠,99.9999%的时间可用。可提供中低数据速率(约50kbps~10Mbps)。支持高速移动性。
5G的用例涵盖了许多方面:
网络切片 (Network Slicing)是一种虚拟化,它允许在一个共享的物理网络基础架构上运行多个逻辑网络,每个逻辑网络之间是隔离的,并且能够提供定制的网络特性,如带宽、延时、容量等。同时,每个逻辑网络里除了网络资源外,还包含了计算和存储资源。网络切片是5G至关重要的特性,但它本身并没有局限在5G的范围里。
不同的行业对网络的需求不一样:物联网需要的是大容量网络,但是对时延和带宽要求不高;自动驾驶要求的是低时延网络;而视频终端要求的是大带宽。5G网络如何同时满足这些需求?一种方法是为每种需求创建特定的网络,另一种方法就是通过网络切片,将一个5G网络划分成满足不同需求的多个分片,每个分片对应不同的需求,分片之间互不影响。这样,一个5G网络可以同时满足多个场景的不同组网需求。
窄带物联网 (NB-IoT, Narrow Band Internet of Things)是物联网领域的新兴技术,支持低功耗设备在广域网的蜂窝数据连接,只消耗大约180kHz的带宽,可直接部署于GSM网络、UMTS网络或LTE网络,以降低部署成本、实现平滑升级。NB-IoT支持待机时间长、对网络连接要求较高设备的高效连接。
低功耗广域网 (LPWA, Low-Power Wide-Area Network)是一种用在物联网(如以电池为电源的感测器)、可以用低比特率进行长距离通讯的无线网络。LPWAN每个频道的传输速率为0.3~50kbps。
LTE Cat M1 是专为物联网和机器对机器通信而专门设计的LPWA技术。它用于支持低于1Mbps的上传/下载数据速率的低到中等数据速率应用,并且可以在半双工或全双工模式中使用。LTE CAT M1使用现有的LTE网络进行操作,其优点之一是它具有从一个小区站点向另一个小区站点之间切换的能力,可以在移动应用中使用。LTE Cat M1能够与2G、3G和4G网络共存,具有移动网络的所有安全和隐私功能的优点。
远距离无线电 (LoRa, Long Range Radio)的最大特点是,在同样的功耗条件下比其他无线方式传播的距离更远,在同样的功耗下它比传统的无线射频通信距离扩大3-5倍。
Sigfox 是一种全球部署低的LPWA,用户设备集成支持Sigfox协议的射频模块或芯片、并开通连接服务后,即可连接到Sigfox网络,享受物联网连接服务。Sigfox是一种低成本、低功耗的可靠解决方案,用于连接传感器和设备。
无线智能普适网络 (Wi-SUN, Wireless Smart Ubiquitous Networks)是一种通讯协议,具有传输距离远、省电等特性。在日本政府的推广之下,Wi-SUN技术在日本区域市场的渗透率逐渐提升,已逐渐进入智能电表、智能家居(如智能门锁)等领域。
[空行]
[空行]
数字孪生是现实世界实体或系统的数字化表示。数字孪生的实现是一种封装的软件对象或模型,可反映唯一的物理对象(请参见附注4)。可以汇总来自多个数字孪生的数据,以跨多个现实世界的实体(例如电厂或城市)进行合成视图。
数字孪生的基本要素是:
模型 :
数字孪生模型是真实对象的功能系统模型。数字孪生包括现实对象的数据结构、元数据和关键变量。可以从更简单的原子数字孪生组装更复杂的复合数字孪生。
数据 :
与现实世界对象相关的数字孪生的数据元素包括:身份、时间序列、当前数据、情境数据和事件。
唯一性 :
数字孪生对应于唯一的物理事物。
监控能力 :
数字孪生可用于查询实际对象的状态,或接收粗略或细化的通知(如基于API)。
[空行]
设计良好的资产数字孪生,可以显著改善企业决策。它们在边缘与真实世界的对象链接在一起,用于了解物件或系统的状态、响应变化、改善操作、增加价值。
组织将首先简单地实施数字孪生,并随着时间的推移逐步发展,从而提高收集和可视化正确数据、应用正确的分析和规则以及有效响应业务目标的能力。数字孪生模型将激增,随着供应商越来越多地向客户提供这些模型,作为其产品不可或缺的一部分。
[空行]
“The Future Shape of Edge Computing: Five Imperatives”
“Ask These Four Questions About Enterprise 5G”
“Digital Business Will Push Infrastructures to the Edge”
“Five Approaches for Integrating IoT Digital Twins”
“Why and How to Design Digital Twins”
“The Technical Professional’s Guide to Edge Infrastructure”
“How Edge Computing Redefines Infrastructure”
[空行]
[空行]
[空行]
[空行]
趋势7:分布式云
(Distributed Cloud)
[空行]
分布式云是指将公有云服务分发到云提供商的数据中心之外的不同位置,而原始的公有云提供商则负责运行、治理、维护和更新。这代表大多数公有云服务的集中化模式的重大转变,并将引领云计算的新时代。
作为一种计算方式,云计算 使用互联网技术提供弹性可伸缩IT能力的服务化。长期以来,云计算一直被视为提供商数据中心中运行的“集中式”服务的代名词。但是,出现了私有云和混合云选项,可以补充公有云模型。私有云是指为通常在自有数据中心中为不同内部公司创建专用的云服务。混合云是指集成私有云和公有云服务,以支持并行、集成或互补的任务。混合云的目的是以优化、高效和经济高效的方式,将提供商的外部服务与内部运行的内部服务混合在一起。
实施私有云非常困难。大多数私有云项目都无法提供组织寻求的云计算成果与收益[37] 。此外,Gartner与客户就混合云进行的大多数对话显示,它们实际上并不是真正的混合云方案。相反,它们是关于混合IT场景的,在这些场景中一系列类似云的模式将非云技术与公有云服务结合使用。混合IT和真正的混合云选项可能是有效的方法,我们建议在某些关键用例中使用。但是,大多数混合云破坏了许多云计算价值主张,包括:
[空行]
[空行]
云服务的位置是分布式云计算模式的关键组成部分。从历史上看,位置与云定义无关,尽管与位置有关的问题在许多情况下很重要。随着分布式云的到来,位置正式进入云服务的定义。由于多种原因,位置可能很重要,包括数据主权和对时延敏感的用例。在这些情况下,分布式云服务为组织提供了在满足要求位置提供的公有云服务的能力。
在超大规模公有云实施中,公有云是“宇宙的中心”。但是,几乎从服务开始就已经在公有云中向全球分发了云服务。这些提供商现在在世界各地具有不同的区域,所有区域均由公有云提供商进行集中控制、管理和提供。分布式云将该模式扩展到云提供商拥有的数据中心之外。在分布式云中,原始公有云提供商负责云服务架构、交付、运营、治理和更新的所有方面。这将恢复在客户负责交付的一部分时被打破的云价值主张,而且在混合云场景中通常都是如此。云提供商不需要拥有安装分布式云服务的硬件。但是,在完全实施分布式云模式时,云提供商必须对如何管理和维护该硬件承担全部责任。
我们预计,分布式云计算将分三个阶段进行:
数据主权 (data sovereignty)是指,指以二进制、数字形式转换和存储的信息,应受其所在国家法律的约束。
当前围绕数据主权的许多担忧,都与执行隐私法规和防止存储在外国的数据受到东道国政府的传唤有关。
云服务的广泛采用、以及包括对象存储在内的数据存储新方法,比以往任何时候都更能打破传统的地缘政治障碍。作为回应,许多国家通过修改现行法律或颁布新的法规来规范新的合规性要求,要求将客户数据保存在客户居住的国家内。
很难验证仅在允许的位置存在数据。它要求云客户信任其云提供商在托管服务器的位置上是完全诚实和开放的,并严格遵守服务级别协议(SLA)。
[空行]
分布式云支持从“分布”到特定且不同位置的公有云服务的连续连接和间断连接操作。这可以实现低时延的服务执行,其中云服务更接近远程数据中心的需求点,或者一直到边缘设备本身。这可以极大地提高性能,降低与全球网络相关的中断的风险,并支持偶尔连接的场景。到2024年,大多数云服务平台将至少提供一些在需求点执行的服务。
需求点 (point of need)原为军事术语,指在分布式行动中,由地域作战指挥官或下属指挥官指定为部队或物资接收点所需工作区域的物理位置,以供后续使用或消耗。
[空行]
[空行]
分布式云还处于发展的早期阶段。许多提供商的目标是长期以分布式的方式提供大部分公共服务。但是目前,它们仅能以分布式方式提供其服务的子集,而且通常是一个小子集。某些提供商的方法不支持完全分布式云的完整交付、运行和更新要素。提供商通过Microsoft Azure Stack、Oracle Cloud at Customer、Google Anthos、IBM Red Hat和AWS Outposts等产品,将服务扩展到第三方数据中心,并扩展到边缘。企业应该评估可能会看到的三种方法的潜在收益和挑战:
Microsoft Azure Stack是一个混合云平台,可在数据中心中交付Azure服务。该平台旨在支持企业不断发展的业务需求。 Azure Stack可以为现代应用启用新方案,例如边缘和断开连接的环境,或满足特定的安全性和合规性要求。
Oracle Cloud at Customer是一项完全托管的服务,可在公司自己的数据中心中运行。 Oracle提供硬件、安装软件、管理日常运营并提供持续支持,所有这些都需要按月订阅。
Google Anthos是一个开放的应用程序现代化平台,可让现有应用程序现代化、构建新应用,并在任何地方运行它们。 Anthos建立在Google率先开发的Kubernetes、Istio和Knative等开源技术的基础上,可实现内部部署和云环境之间的一致性。
AWS Outposts是一项完全托管的服务,可将AWS基础设施、AWS服务、API和工具扩展到几乎任何数据中心、托管位置或本地设施,以提供真正一致的混合体验。 AWS Outposts非常适合需要低时延访问本地系统、本地数据处理或本地数据存储的工作负载。
[空行]
软件 :
客户购买并拥有带有提供商云服务子集的硬件平台和软件层。提供商对软件或底层硬件平台的持续运行、维护或更新不承担任何责任,由用户自行负责、或托管服务提供商负责。尽管软件方法在公共服务和本地实施之间提供了对等模式,但混合云的其他挑战仍然存在。一些客户认为控制服务更新是一个优势。
可移植性层 :
提供商提供通常在Kubernetes上构建的可移植性层,作为跨分布式环境的服务的基础。在某些情况下,可移植性层只是使用容器来支持容器化应用的执行。在其他情况下,提供商将某些云服务作为可在分布式环境中运行的容器化服务来提供。可移植性方法忽略了底层硬件平台的所有权和管理,这仍然是客户的责任。
分布式服务 :
提供商以硬件/软件结合的形式提供某些云服务的对等版本,并且提供商负责管理和更新服务。这减轻了可以将服务视为“黑匣子”的消费者的负担。但是,某些客户会不愿放弃对底层硬件和软件更新周期的所有控制权。尽管如此,我们预计这种方法将随着时间的推移而占主导地位。
[空行]
[空行]
分布式云的基本理念是,公有云提供商负责设计、架构、交付、运行、维护、更新和所有权,包括底层硬件。但是,随着解决方案越来越靠近边缘,由提供商拥有整个技术栈往往是不希望的或不可行的。由于这些服务被分发到运营系统(如发电厂),因此消费组织不会将物理工厂的所有权和管理权交给外部供应商。但是,消费组织可能会对提供商提供设备的交付、管理和更新服务感兴趣。移动设备、智能手机和其他客户端设备也是如此。因此,我们期望出现各种交付模式、提供商接受 不同级别的所有权和责任。
会影响公有云服务分布的另一个边缘因素,将是边缘、近边缘和远边缘平台的能力,它们可能不需要或无法运行镜像集中式云的对等服务。针对目标环境量身定制的补充服务(例如低功能IoT设备),将成为各种分布式云一部分(例如AWS IoT Greengrass)。 但是,如果要将这些服务视为分布式云的一部分,那么云提供商至少必须设计、架构、分发、管理和更新这些服务。
AWS IoT Greengrass可以无缝地将AWS扩展到边缘设备,以便它们可以在生成的数据上进行本地操作,同时仍将云用于管理、分析和持久存储。借助AWS IoT Greengrass,已连接的设备可以运行AWS Lambda函数和/或Docker容器,或基于机器学习模型执行预测,保持设备数据同步,并与其他设备安全通信,即使未连接到互联网也能如此。
[空行]
[空行]
“The Edge Completes the Cloud: A Gartner Trend Insight Report”
“Hype Cycle for Cloud Computing, 2019”
“Define and Understand New Cloud Terms to Succeed in the New Cloud Era”
“Prepare for AWS Outposts to Disrupt Your Hybrid Cloud Strategy”
“Rethink Your Internal Private Cloud”
“When Private Cloud Infrastructure Isn’t Cloud, and Why That’s Okay”
“Cloud Computing Primer for 2019”
[空行]
[空行]
[空行]
[空行]
趋势8:自主物件
(Autonomous Things)
[空行]
自主物件是使用AI来自动化人类原有能力的物理设备。最容易识别的自主物件形式,是机器人、无人机、自动驾驶车/船和家用电器。由AI驱动的物联网要素(例如工业设备和消费类设备)也是一种自主物件。每种物理设备都会关注与人有关的操作。它们的自动化超越了刚性编程模式所提供的自动化,它们利用AI来提供高级行为,从而与周围环境和人进行更自然的互动。自主物件运行于许多环境(陆地、海洋和空中)和不同的控制级别。自主物件已成功部署在高度受控的环境中,例如地雷。随着技术能力的提高、法规的允许和社会认可度的增加,自主物件将越来越多地部署在不受控制的公共场所。
[空行]
[空行]
自主物件的发展非常迅速,部分原因是它们共享一些通用的技术能力。一旦针对一种类型的自主物件克服了开发能力的挑战,该创新便可以应用于其他类型的自主物件。基于2020 NASA技术分类法,可将自主物件 通用能力和技术列举如下[ 38] :
NASA从事各种技术开发活动,通过扩大航空、科学和太空领域的知识和能力来执行NASA的任务。为了管理和交流这一广泛而多样的技术组合,NASA使用了技术分类法。此分类法可以识别、组织、交流与推进与NASA任务有关的技术领域。
2020 NASA技术分类法 包含17种不同的基于技术学科的分类法,并为每个技术领域提供了细分结构。分类法使用三级层次结构来对技术类型进行分组和组织。1级代表技术领域,即该领域的名称(如TX01: 推进系统)。级别2是子领域域列表(如TX01.1 化学空间推进)。第3级对子领域内的技术类型进行了分类(如TX1.1.1 集成系统和辅助技术)。还包括示例技术部分,提供相关技术的简要示例。
感知 :
了解机器运行的物理空间的能力。这包括了解空间中的表面、识别物及其轨迹,以及解释环境中的动态事件等。
交互 :
使用各种渠道(如屏幕和音箱)和感官输出(如光、声音和触觉)与人类和物理世界中的其他事物进行交互的能力。
移动 :
通过某种形式的推进力(如步行、巡航/潜水、飞行和驾驶)安全地导航,并从空间中的一点移动到另一点的能力。
操控 :
操纵空间中的对象(如抬起、移动、放置和调整)和修改对象(如切割、焊接、绘画和烹饪)的能力。
协作 :
通过与不同事物的协作来协调动作,并将动作组合在一起,来完成多主体组装、航道合并和群体移动等任务的能力。
自主 :
能够以最少的外部输入完成任务,并能够响应动态变化的空间,而无需依靠基于云的处理或其他外部资源的能力。
在探索自主物件的特定用例时,首先要了解物件运行的空间以及与之交互的人、障碍、地形和其他自主对象。例如,在街道上导航比在人行道上容易得多,因为街道上要遵循车道、交通信号灯、标志和规则。然后,考虑希望通过自主物件实现的结果。最后,考虑解决已定义场景所需的技术能力。
[空行]
[空行]
自主物件运行于一系列自主环境, 从半自主、到完全自主。 “自主”一词在用于描述自主物件时,需要进行解释。当Gartner使用此术语来描述自主物件时,我们的意思是这些物件可以在所定义的情境中不受监督地操作或完成任务。自主物件可能具有各种自主程度。例如,自动定向的吸尘器可能具有有限的自主性和智能性,而无人驾驶飞机可能会自动避开障碍物。
在考虑任何自主物件的用例时,可以使用通常用于评估自动驾驶汽车的自主性级别[39] :
无自动化 :
人工执行所有控制任务。
人工辅助的自动化 :
人工执行所有控制任务,但设计中包含一些控制辅助功能。操作员仍然负责操作,但是可以自动执行特定的简化控制功能。
部分自动化 :
人工负责控制任务和监视环境,但是某些控制任务是自动化的。事件将能够在短期内或在特定情况下自主运行,但操作员进行持续的控制。
有条件的自动化 :
控制任务是自动化的,但是需要人工在自动化系统的要求下随时接管控制任务。在某些操作范围内,可以进行自主操作。事件可以完成特定的任务,但是在短期可能需要人工干预。
高度自动化 :
控制任务在选定条件下是自动化的,但是在这些选定条件之外操作时,需要人工来接管控制任务。物件自动完成要求的任务,并且能够做到,但是如果环境变化超出特定范围,则可能需要人工干预。
完全自动化 :
控制任务在所有情况下都是自动化的。人工在要求下接管控制任务。物件可以在没有人工干预的情况下完成所有预期的任务,并且能够调整过程、变更参数,并决定何时只是部分完成任务。
另一个考虑因素与自治程度无关,而是要求或期望的指示或控制程度。即使是完全自主的、且可完全独立于任何外部主体(例如人)运行的自主物件,也可能需要插入一定程度的控制或指示。例如,在自动驾驶汽车中,人将指示目的地和驾驶经验的一些问题,并在需要时能够控制汽车。将自主和控制视为互补的两面,才能恰当定义特定的自主物件用例。
[空行]
[空行]
随着自主物件的激增,我们预测单独的智能物件将向智能物件协作群转变。在群体模式中,多个设备将独立于人或人工输入而协同工作。例如,异构机器人可以运行在协调的组装流程中[40] 。在物流市场,最有效的解决方案可能是使用自动驾驶车辆将包裹移至目标区域,车辆上的机器人和无人机可能会影响包裹的最终交付。美国国防高级研究计划署(DARPA)在这一领域处于领先地位,并且正在研究使用无人机群攻击或捍卫军事目标的可能性[41] 。其他示例包括:
英特尔在2018年冬季奥运会开幕式上使用无人机群[42]
在本田的SAFE SWARM,车辆可与基础设施相互通信,以预测危险并优化交通流量[43]
波音的Loyal Wingman 计划部署了一系列无人机,它们可以与领航飞机上控制的无人机一起飞行[44]
SAFE SWARM是一种技术概念,旨在通过使用互联汽车技术(互联网连接、车对车、车对基础设施)实现安全、顺畅的交通流量。
Loyal Wingman是波音公司在美国以外最大的无人飞机计划,目标是国际市场。
[空行]
探索由AI驱动的自主功能,可以为组织或客户环境中的物理设备提供虚拟赋能。尽管自主物件提供了许多令人兴奋的可能性,但它们无法匹敌人脑的智能广度和动态通用学习。它们可以专注于范围广泛的目的,尤其是使人类日常活动自动化。可创建业务场景和客户旅程图,识别和探索能带来引人注目业务成果的机会。应寻求将智能物件的使用纳入传统的手动和半自动化任务的机会。业务场景的示例包括:
先进农业 。
美国国家机器人计划等项目,正在将农业自动化推向新高度[45] 。例如创建机器计划算法,以便自主运营农场。
更安全的汽车运输 。
高科技公司(如Alphabet、Waymo、特斯拉、Uber、Lyft和苹果)和传统汽车公司(如特斯拉、通用汽车、奔驰、宝马、日产、丰田和福特),通过消除人为错误因素,让自动驾驶汽车减少事故的发生。我们预计到2025年,每年将生产100多万辆L3级以上的汽车[46] 。
自主船运 。
Kongsberg Maritime等海事公司正在试验各种层面的自动驾驶船只。Fjord1 通过使用Kongsberg制造的自动化系统,使挪威安达和Lote之间运行的两艘渡轮实现了自动化。 Kongsberg还致力于自主集装箱船的开发[47] 。
搜索和救援 。
可以运行各种自主操作,来支持各种环境中的搜索和救援。例如,由多个相连的冗余单元组成的“蛇形机器人”可以在狭小的空间内移动,进行物流不可能或对人不安全的探索。卡内基梅隆大学机器人学院正在试验各种形式和运动模式[48] 。
美国国家机器人计划(NRI , National Robotics Initiative)
Waymo 是一家自动驾驶技术开发公司,是Alphabet的子公司。Waymo最初是Google的一个项目,2016年12月成为独立子公司。2017年4月,Waymo在凤凰城开始了自动驾驶出租车服务的有限试用。2018年12月5日,该服务推出了名为Waymo One的商业自动驾驶汽车服务。
自动驾驶分级 :目前采用较广泛的是美国机动车工程师学会(SAE)的标准,采用L0~L5分级。美国公路交通安全管理局(NHTSA)的分类,则将自动驾驶分为0-4级。
L0:无自动化
没有任何自动驾驶功能、技术,司机对汽车所有功能拥有绝对控制权。驾驶员需要负责启动、制动、操作和观察道路状况。
L1:单一功能级自动化
驾驶员仍然对行车安全负责,不过部分控制权交给系统管理,某些功能已经自动进行,比如常见的自适应巡航(AAC)、应急刹车辅助(EBA)、车道保持(LKS),只是单一功能,驾驶员无法做到手和脚同时不操控。
L2:部分自动化
司机和汽车分享控制权,驾驶员在某些环境中可以不操作汽车,即手脚同时脱离控制。但是驾驶员仍然需要随时待命,对驾驶负责,准备接管汽车。比如:ACC和LKS组合跟车。重点是驾驶员不再是主要操作者。
L3:有条件自动化
在有限情况实现自动控制,汽车自动驾驶负责整个车辆的控制,但是遇见紧急情况,驾驶员仍然需要接管汽车,但是有足够预警时间。解放驾驶员,对行车安全不再负责,不必监视道路状况。比如高速和人流量较少的城市路段。
Level4:完全自动化
行车可以没有人乘坐,汽车负责安全,并完全不依赖驾驶员干涉。
Kongsberg Maritime是一家挪威技术企业,隶属于Kongsberg Gruppen。它提供用于商船和近海设施的定位、测量、导航和自动化系统,最著名的产品是动态定位系统、船舶自动化和监视系统、过程自动化、卫星导航等。
Fjord1 是一家挪威运输集团,成立于2001年。该公司本身是众多子公司的控股公司。公司总部位于弗洛勒,但重要渡轮部门的总部位于莫尔德。它是是挪威运输行业中最大的公司之一。
卡内基梅隆大学机器人学院 成立于1979年,旨在对与工业和社会任务相关的机器人技术进行基础和应用研究。它寻求将实践与理论相结合,在致力于实现机器人技术潜力的同时,在机器人科学方面进行了许多研究。
[空行]
[空行]
“Hype Cycle for Connected Vehicles and Smart Mobility, 2019”
“Hype Cycle for Drones and Mobile Robots, 2019”
“Toolkit: How to Select and Prioritize AI Use Cases Using Real Domain and Industry Examples”
“Swarms Will Help CIOs Scale Up Management for Digital Business”
“Use Scenarios to Plan for Autonomous Vehicle Adoption”
“Supply Chain Brief: Favorable Regulations Will Accelerate Global Adoption of Autonomous Trucking”
[空行]
[空行]
[空行]
[空行]
趋势9:实用区块链
(Practical Blockchain)
[空行]
区块链是网络中所有参与者共享的、可扩展的、加密签名的、不可撤销的交易记录列表[49] 。每条记录均包含时间戳和指向先前交易的参考链接。通过这一信息,具有访问权限的任何人都可以在历史记录的任何时候追溯属于任何参与者的交易事件。区块链是分布式账本概念外延拓宽后的一种体系设计。区块链和其他分布式分类账技术,可在不受信任的环境中提供信任,从而消除对受信中央机构的需求。区块链已成为各种分布式账本产品的通用缩写。
区块链能以多种不同的方式推动价值增长:
区块链通过使分类账独立于各个应用和参与者,并在分布式网络中复制分类账,以创建重大事件的权威记录、消除业务和技术摩擦。拥有访问权限的每个人都可以看到相同的信息,并且通过拥有一个共享的区块链模型来简化整合。
区块链还启用了分布式信任体系结构,允许不认识或彼此固有信任的各方使用各种资产来创造和交换价值。
通过将智能合约用作为区块链的一部分,可以对操作进行编码,并使区块链中的更改触发其他操作。
区块链有潜力通过建立信任、提供透明度和实现跨业务生态系统的价值交换来重塑行业,从而有可能降低成本、减少交易结算时间、并改善现金流。资产可以追溯到来源,大大减少伪造商品替代的机会。资产跟踪在其他领域也具有价值,例如在整个供应链中跟踪食品,可以更轻松地识别污染源,或跟踪单个零件以帮助召回产品。区块链另一个潜力领域是身份管理。智能合约可以被编程到区块链中,事件可以触发动作,例如收货即付款。
根据2019年Gartner的CIO调查,60%的CIO期望在未来三年部署某种区块链[50] 。在已经部署或计划在未来12个月内部署区块链的行业,金融服务业处于领先地位(18%),其次是服务业(17%)和运输业(16%)[51] 。相比其他行业的组织, 这些行业的组织可能更需要对有限使用某些区块链组件来支持简单用例,例如记录保存和数据管理。
[空行]
[空行]
由于一系列技术问题,包括不佳的可扩展性和互操作性,区块链对于企业部署仍不够成熟。区块链的关键革命性创新是,它消除了对任何中央或“授权”权威机构信任的所有需求。它很大程度上是通过分散的公众共识来实现的,而这种共识尚未在企业区块链中使用,而企业区块链是组织和联盟管理成员资格和参与的。但是事实证明,企业区块链是数字化转型的关键支柱,支持整个商业生态系统中信任度和透明度的变革式和渐进式改进(请参阅“阐明区块链:确定组织的适用性[Blockchain Unraveled: Determining Its Suitability for Your Organization]”)。
到2023年,区块链将可技术上进行扩展,并将以必要的数据机密性支持可信赖的私有交易。这些发展,首先被引入公有区块链。随着时间的流逝,授权区块链将与公有区块链整合。它们将开始利用这些技术改进的优势,同时支持授权区块链的成员资格、治理和运营模式要求(请参阅“区块链技术的炒作周期,2019年[Hype Cycle for Blockchain Technologies, 2019]”)。
区块链必须是信息和价值交换网络的一部分,否则区块链几乎不会增加价值。网络协作挑战最初促使组织转向联盟,以便从区块链中获得最直接的价值。选择一个联盟需要在众多风险标准下进行尽职调查,然后再共享数据、并与外界合作。了解和评估这些风险,对于从联盟参与中获取价值至关重要。存在四种类型的联合体:以技术为中心;以地域为中心;以行业为中心;以流程为中心。一种选择是与整个行业的联盟合作,但是其他类型的联盟也值得探索。组织需要仔细考虑这些联盟将如何影响企业参与特定行业和竞争格局。
区块链有三种类型:
公有链 :
全世界任何人都可以读取的、任何人都可能发送交易且交易能获得有效确认的、任何人都能参与其中共识过程的区块链。共识过程决定哪个区块可被添加到区块链中和明确当前状态。公有链就是完全去中心化。
特点:保护用户免受开发者的影响;访问门槛低;所有数据默认公开。
公有链目前的应用有:比特币、以太坊、超级账本与众多的山寨币以及智能合约,其中公有链始祖为比特币。
私有链 :
写入权限仅在某个组织或机构控制的区块链,读取权限或者对外开放,或者某种程度地进行了限制。
特点:交易速度非常之快;给隐私更好的保障;交易成本大幅降低、甚至为零;有助于保护基本的产品不被破坏。
私有链目前的应用有:Linux基金会、R3 CEV平台以及Gem Health网络的超级账本项目等。从各个大国国际金融巨头陆续加入R3 CEV区块链计划来看,金融集团之间更倾向于私有链(也有人认为这是联盟链)。
联盟链 :
若干个机构共同参与管理的区块链,每个机构都运行一个或多个节点,其中的数据只允许系统内不同的机构进行读写和发送交易,并且共同来记录交易数据。联盟链的每个参与方不用担心自己数据存在哪里,自己产生的数据都只有自己看到,只有通过对方授权的密钥才能看到其他参与者的数据,这样就能解决数据隐私和安全性问题,同时能够实现去中心化。
特点:更好的保护各方隐私;互相监督,互相发展。
联盟链是私有链进一步进化的产物,相对于私有链与公有链,联盟链更有前景,能更好地发挥互联互通、共享信息的作用,也能促成更快的建立生态联盟、利用区块链技术去改变工作模式和生活模式。
联盟链与私有链有很多相似之处,但两者设计隐私权限会有很多不同。
基于三种区块链,出现了跨链和侧链的概念。
跨链 :
通过一个技术,让价值跨过链和链之间的障碍,进行直接的流通。
简单地说,就是信息从一条链到另外一条链,也就是作为资产的token从一条链去往另一条链,即资产交换。
侧链 :
侧链是指,可以让比特币安全地从比特币主链转移到其他区块链、又可以从其他区块链安全地返回比特币主链的一种协议。
[空行]
[空行]
Gartner已确定多种区块链的用例,它们包括:
资产跟踪 。
这些用例涵盖了整个供应链中对有形资产的跟踪,以准确地确定位置和所有权。例如,通过贷款流程跟踪车辆、艺术品售后以及海运和备件的位置。
索赔 。
此类用例涵盖汽车、农业、旅行、人寿和健康保险等领域的自动索赔处理。它还包括处理产品召回等 其他索赔。
身份管理/了解您的客户( KYC) 。
此类用例涵盖了必须将记录牢固地绑定到个人的用途。例如,管理教育成绩、患者健康、选举身份和国民身份的记录。
内部记录保存 。
在这些用例中,需要保护的数据保留在单个组织内。示例包括主数据管理、内部文档管理、采购订单和发票记录以及库存记录保存。
忠诚度和奖励 。
此类包括用于跟踪忠诚度积分(针对零售商、旅游公司和其他公司),并提供内部奖励(例如给员工或学生)的用例。
付款/结算 。
此类用例涉及当事方之间的付款或交易的结算。示例包括特许权使用费支付、股票结算、银行间支付、商业贷款、采购到付款处理和汇款处理。
溯源 。
与资产跟踪用例类似,它涵盖了记录资产的移动,但是目的是显示资产的完整历史和所有权,而不是其位置。示例包括:跟踪生物样本和器官;确定葡萄酒、咖啡、鱼和其他食品的来源;证明组件的真实性;跟踪药品的生命周期。
共享记录保存 。
此类包括需要在多个参与者之间安全共享数据的用例。例如,公司公告、多方酒店预订管理、航班数据记录和监管报告。
智能城市/物联网 。
本组包括使用区块链为智能空间或物联网解决方案提供数据跟踪和控制功能的用例。示例包括对等能源交易、电动汽车充电管理、智能电网管理和废水系统控制。
贸易融资 。
这些用例旨在简化贸易融资流程,包括管理信用证、简化贸易融资、促进跨境贸易。
交易 。
本组中的用例旨在改善资产买卖过程,包括衍生产品交易、私募股权交易和体育交易。
随着区块链技术的发展,Gartner预测至少另外三个用例将变得更加可行,并可以证明区块链带来的革命性收益:
基于区块链的投票 将受益于诸如与区块链相关的安全性、分叉管理、系统治理和分类账互操作性等改进。区块链还可以改善投票记录和选民名册的跟踪和可追溯性。
基于区块链的自我主权数字身份 也将变得更加现实。这可以让全球使用的多对多次优身份验证系统和关系更加合理化。
加密货币支付和汇款服务 将在恶性通货膨胀率较高的国家使用,并保持购买力和财务状况。
尽管区块链面临重重挑战,但它颠覆和创收的巨大潜力意味着,你应该开始评估区块链,即使近几年并不准备积极采用区块链技术。区块链开发的实用方法要求:
要确定内部和提供商如何使用“区块链”术语,并为内部讨论制定明确的定义。在与定义不明确/不存在区块链产品的供应商进行交流时,或将传统产品重新封装为区块链解决方案时,请多加小心。
使用Gartner的区块链发展阶段模型[52] ,可以更好地评估分类账的发展,包括共识机制开发、侧链和区块链等相关计划。在资源允许的情况下,可以将分布式分类账视为概念证明(POC)式发展。但是,在开始分布式分类账项目之前,请确保你的团队拥有商务和密码学技能,以了解什么是可能的和不可能的。要确定与现有基础架构的集成点,以确定必要的投资,并监视平台的演进和成熟度。
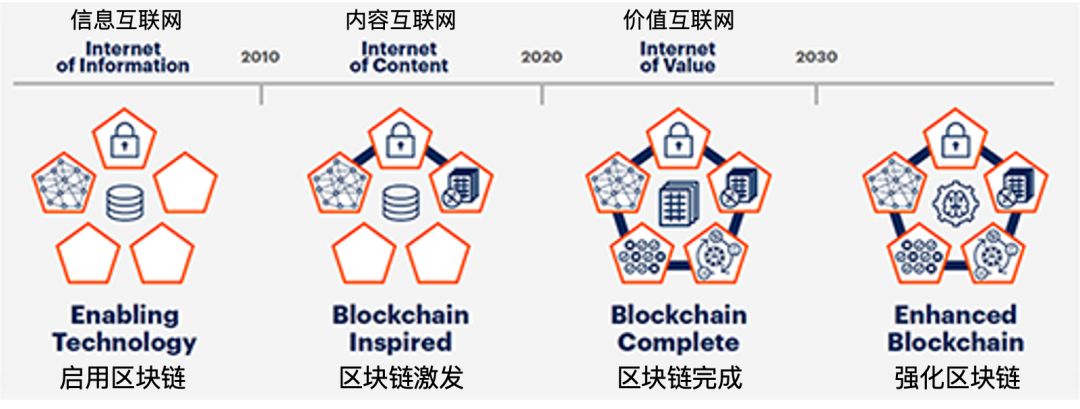
Gartner认为,真实区块链包含五大元素:分布式,加密,不可更改性,通证化,去中心化。组合使用这些元素,组织可以发挥区块链的真正优势,这两个或多个元素在数字环境中安全地交互,并交换新形式的价值和资产。
基于此,Gartner提出区块链发展的四阶段模型。
启用区块链
加密、分布式计算、对等网络和消息传递等 技术,为构建未来的区块链解决方案提供了基础。这些技术还可以用作非块链解决方案的一部分,例如,提高分布式数据管理系统的运营效率。
区块链激发
区块链激发的解决方案使用以下五个元素中的三个:分布式、加密和不可变更性。这意味着,解决方案专注于效率或重新设计现有流程。例如,阿里巴巴跟踪来自世界各地的食品。
受区块链激发的解决方案将在2020年代初主导企业实施重点。这些解决方案通常范围有限,并且依赖于维护建立过程和架构,例如集中式公证、分布式或复制数据存储,哈希/签名和消息传递等。
区块链完成
从2023年左右开始,企业就绪的区块链完整解决方案将出现。它们将利用所有五个区块链元素,并为使用动态智能合约、通证化和去中心化运营架构的全新商业模式提供途径,实现区块链的全部价值主张。
完整的区块链解决方案将具有通过智能合约和去中心化实现通证化的功能,它是引入新商业模式的催化剂。引入和使用支持区块链的通证,将允许以前不可能的价值交换系统。
强化区块链
进入2025年,区块链将融合互补技术,例如物联网(IoT)、人工智能(AI)和去中心化的自我主权身份(SSI)。
这种发展将使人们能够通过分散的SSI,拥有、控制和共享数字和非数字身份。个人将能够决定如何共享身份,从而使组织、个人或物件可以根据交互需要使用身份数据。例如,所有数据将被保护在数字钱包中,并且可追溯、可追踪。
这些解决方案还将扩展通证化的价值类型,并增加智能合约支持的微交易数量。例如,这可能让汽车可以根据传感器收集的数据,直接与保险公司协商自己的保险费率。
强化区块链的解决方案,将导致商业模式发生变化,因为自主代理获得了与人类进行商业互动和独立运作的能力。
[空行]
[空行]
“Hype Cycle for Blockchain Technologies, 2019”
“Blockchain Technology Spectrum: A Gartner Theme Insight Report”
“The Future of Blockchain: 8 Scalability Hurdles to Enterprise Adoption”
“Use Gartner’s Blockchain Conceptual Model to Exploit the Full Range of Possibilities”
[空行]
[空行]
[空行]
[空行]
[空行]
在未来五年,人工智能、尤其是机器学习,将在广泛的用例中用于增强人类的决策能力。同时,物联网、云计算、微服务和智能空间中高度连接的系统中,潜在的攻击点将大大增加。虽然这为实现超自动化和利用自主物件提供了巨大的机会来实现业务转型,但同时给安全团队和风险领导者带来了重大的新挑战。在考虑AI如何影响安全空间时,需要探索三个关键观点:
保护AI驱动的系统 。这需要保护AI训练数据、训练管道和ML模型。
利用AI强化安全防御 。它使用ML来了解模式、发现攻击并自动化网络安全流程的各个方面,同时增强人类安全分析人员的行动。
预期攻击者会恶意使用AI 。识别并防御攻击,将是网络安全角色的重要补充。
[空行]
[空行]
AI产生了新的攻击表面,因此增加了安全风险。就像安全和风险管理负责人会扫描资产中的漏洞、并用补丁进行修复一样,应用负责人必须监视ML算法及其提取的数据,以确定是否存在已有或潜在的损坏(“中毒”)问题。如果受到感染,则可能使用数据操纵来破坏数据驱动的决策,而决策 需要数据质量、完整性、机密性和隐私性。
ML管道有五个阶段需要保护:数据采集;准备和标注;模型训练;推理验证;生产部署。在组织需要计划的每个阶段,都有各种类型的风险。到2022年,所有AI网络攻击中有30%将利用训练数据中毒、AI模型盗窃或对抗性样本攻击AI驱动的系统53] 。
机器学习可以应用于各种各样的数据类型,如向量、文本、图形和结构化数据,并包含转换器( Transformer)、模型学习器(Estimators)等主要组件。
ML管道 (ML Pipeline)是 帮助自动化机器学习的工作流程和步骤。ML管道不是单向流动,其流水线是循环迭代的,每个步骤都可以重复执行,从而不断提高模型的准确性,并获得成功的算法、使模型可扩展。
当今许多ML模型都是“训练过的”神经网络,能够执行特定任务或提供从“发生了什么”到“可能发生什么”(预测分析)的洞察力。这些模型很复杂,并且永远不会完成,而是通过重复数学或计算过程将其应用于先前的结果,并在每次进行改进,以使其更接近“解决问题”。
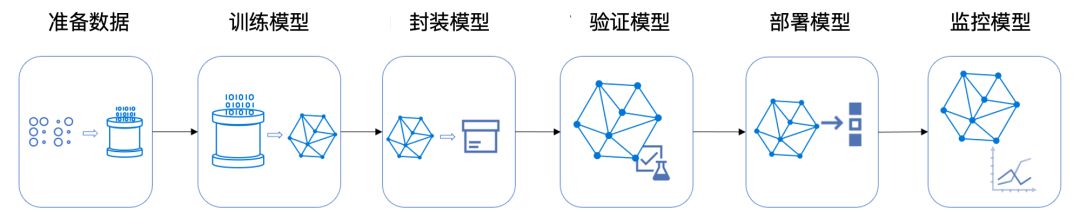
典型的ML管道包括以下过程:
下图为Azure机器学习管道。
[空行]
训练数据中毒 :
黑客可能未经授权访问训练数据,并通过向AI系统提供不正确或受损的数据而导致AI系统发生故障。训练数据中毒在在线学习模型中更为普遍,因为它会在新数据来临时建立和更新输入。在用户提供的数据上进行训练的ML系统,也容易受到训练数据中毒的攻击[54] ,恶意用户会以破坏学习模型为目标提供不良的训练数据。通过限制每个用户贡献的训练数据量、并检查每个训练周期后预测的变化,可以减少数据中毒的风险。
模型失窃 :
竞争对手可以对ML算法进行逆向工程或实施自己的AI系统,从而将算法的输出用作训练数据。如果竞争对手或不良行为者可以观察到输入到AI中的数据、并报告输出结果,他们就可以使用这些数据来开发自己的ML模型,进行监督学习、重构算法[55] 。研究表明,某些深度学习算法特别容易受到这种模仿和操纵[55] 。通过检查日志中是否存在异常数量的查询或更高查询量,可检测模型失窃,并依靠阻止攻击者、准备备份计划来保护预测机器。
对抗性样本 :
分类器容易受到单个输入/测试数据样本的影响,样本稍作更改就能造成AI分类器分类错误。大多数机器学习分类器,例如线性分类器(逻辑回归、朴素贝叶斯分类器)、支持向量机、决策树、增强树、随机森林、神经网络和最近邻,都容易受到对抗性样本的攻击[56] 。对更改进行细化,能使人类观察者不会注意到更改,但是分类器仍然会犯错。可通过部署各种预测机器来主动防御对抗性样本,并生成对抗样本、将其包含在训练数据集中。
机器学习可以分为三种形式:
监督学习( supervised learning)
必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,就知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。
非监督学习 (unsupervised learning)
无监督学习,即在未加标签的数据中,试图找到隐藏的结构。数据没有类别信息,也没有给定的目标值。
非监督学习包括的主要类型:
此外,无监督学习还可以减少数据特征的维度,以便使用二维或三维图形更加直观地展示数据信息。
在传统的监督学习中,机器学习的主要任务是:
常见的分类回归器有:
线性回归 (linear regression)
顾名思义,线性回归是假设数据服从线性分布的,这一假设前提也限制了该模型的准确率,因为现实中由于噪声等的存在很少有数据是严格服从线性的。
逻辑回归 (logistic regression)
从线性回归衍生而来,将线性的值域压缩在(0,1)范围内。与线性回归一样,也要求数据是无缺失的。
朴素贝叶斯 (Naive Bayes)
这一模型适合用在文本样本上,采用了朴素贝叶斯原理假设样本间是相互独立的,因此概率计算大大简化,节省内存和时间,但在关联比较强的样本上效果较差。
支持向量机 (SVM, support vector machine)
SVM是将低维无序杂乱的数据通过核函数映射到高维空间,通过超平面将其分开,因而计算代价比较大。SVM是通过支撑面做分类的,不需要计算所有的样本,高维数据中只需去少量的样本,节省了内存。
决策树 (DT, decision tree)
DT对数据要求度最低的模型,数据可以缺失,可以是非线性的、可以是不同的类型,最接近人类逻辑思维的模型,可解释性好。但在训练数据上比较耗时。
增强树 (boosted trees)
也叫梯度增强回归树(gradient boosted regression tree),弱分类器按照一定的计算方式组合形成强的分类器,分类器之间存在关联,最终分类是多个分类器组合的结果。
随机森林 (random forest)
随机抽取样本形成多个分类器,通过少数服从多数的方式决定最终属于多数的分类器结果,分类器之间是相互去之间关联的。
K近邻 (K Nearest Neighbor)
k个训练样本和测试样本距离最近,然后在k个样本里找出现频率最高的,这就是测试样本的类别。K近邻是无参数训练的模型,但k需要人为设定,且算法的复杂度很高。
[空行]
[空行]
随着攻击的速度和类型的扩大,网络安全专业人员将发现越来越难以满足对更多使用AI进行过滤和自动化防御活动的需求。安全工具供应商正在使用ML来增强工具、决策支持和响应操作。随着研究、框架和算力的商品化,经过精心设计的ML对于可以访问大量相关、高质量训练数据的供应商而言是可行的。应评估解决方案和体系结构,并向供应商挑战ML相关的最新攻击技术,包括ML中的数据中毒、对抗性输入、生成性对抗性网络以及其他安全性相关的创新。
针对特定的高价值用例(例如安全监控、恶意软件检测或网络异常检测)时,基于ML的安全工具可以成为工具包的强大补充。监督学习、无监督学习和强化学习如今已成功用于安全性,以解决恶意软件、网络钓鱼、网络异常、敏感数据的未授权访问、用户行为分析、漏洞优先级划分等。但是,最好的工具并不只是使用ML,它可以提供更好的结果。应重视详尽评估和测试供应商的主张,确保他们实现承诺的价值[57] 。
设计良好的基于ML的安全技术,比基于规则的技术更难被攻击者逃避。但是,ML的概率特性可能会产生许多误报,使警报更难以分类、并增加调整的复杂性。
一般来说,在防御中使用ML会迫使攻击者更改技术。通常,攻击变得更加复杂、因此也代价更高,但并非没有可能。作为响应,安全工具供应商和网络安全专业人员开发新的ML技术,以阻止这些新的攻击技术。这种长期的来回关系将继续下去,安全团队需要为不断升级的策略做好准备。
攻击者正在迅速创新,改进方法攻击安全解决方案中使用的ML技术。他们试图让训练数据染毒、并欺骗预测算法,使之分类错误。要准备好攻击者会完善攻击技术,并通过基于ML的安全技术逃避检测。不要将ML视为安全解决方案中的单一预防技术。
基于ML的安全工具不能完全替代现有的传统工具。应投资基于ML的工具,以增强安全分析师。理想情况下,基于ML的工具将在一定水准上实现自动化,使安全分析人员有更多时间聚焦更复杂、更新颖的攻击方案。
ML算法还可用于改善数据的跟踪和分类,同时提供更准确的报告,并提高总体工作水平,以实现对GDPR等隐私法规的遵从。ML的强大能力,来自可以识别数据集内、跨数据集模型的算法。要从隐藏信息中发掘这一能力,以免让公司脱离GDPR合规性。聊天机器人(chatbot)技术和自然语言处理,可用于合规性仪表板、威胁分类、安全运行中心(SOC)手册和报告自动化。组织可以开 通过使用AI应用自动化,发现和正确记录所有类型的数据和数据关系的过程,发隐隐藏在所有结构化和非结构化数据源中的合规性相关的个人数据的全面视图。使用传统解决方案和手动流程开发全面视图,几乎是不可能的任务[58] 。
[空行]
[空行]
随着攻击者开始使用ML和其他AI技术来为其攻击提供动力,下一个AI相关的安全问题的前沿正在兴起。攻击者才刚刚开始利用ML。他们在许多安全领域中探索机器学习,并助力于机器学习工具的商品化和训练数据的可用性。
机器学习中的每一个新的、令人兴奋的创新,都可以、且必将被恶意使用。攻击者使用机器学习改进目标定位、漏洞利用、新漏洞发现、新负载设计和逃避追踪。
组织必须了解对手如何在训练和预测阶段攻击基于机器学习的安全解决方案,以及机器学习如何加速攻击方法的创新[59] 。
攻击者会利用ML来加速攻击技术的创新。ML工具的商品化,导致许多如何将ML用于邪恶目的的实验。行业的一项积极发展是,由于AI有可能被用于恶意活动,研究人员已开始在AI出版物和代码上使用一些技巧[60] 。尽管如此,安全专业人员应了解这些发展,并制定相应的应对措施。
机器学习在攻击探索中的第一个应用是网络钓鱼。 ML非常适合消化大量数据,例如电子邮件或社交媒体内容。在网络钓鱼攻击中,机器学习可用于识别目标,学习正常的通信模式,然后利用相同的通信方式利用该信息进行网络钓鱼。这对于社交媒体非常有效,因为通常不会缺少可以自动解析的数据。2018年,云安全公司Cyxtera构建了一个基于ML的网络钓鱼攻击生成器,它接受了超过1亿次特别有效的历史攻击的训练,能优化并自动生成有效的诈骗链接和电子邮件[61] 。Cyxtera称,通过使用基于开源库、并经过公共数据训练的AI,它能够在15%的时间内绕过基于AI的检测系统,而传统方法仅能在0.3%的时间中实现这一目标。
身份欺骗通常是网络钓鱼的一部分。攻击者的意图是获得收件人的信任。对于攻击者来说,好消息是机器学习的巨大进步使身份欺骗的可信度超出了几年前的预期。ML可用于在“钓鱼”攻击或语音验证系统中模拟某人的语音。 ML可用于在视频中伪造人物。这种邪恶的机器学习通常称为“深度造假(deepfakes)”。邪恶的ML可以学习什么是正常的,并在“学会正常”之后调整攻击。它可以学习、模拟和滥用写作风格、社交图表和交流方式,以此欺骗他人。
恶意使用ML的另一个最新示例是DeepExploit 。 DeepExploit使用Metasploit。它在服务器上训练,并根据目标主机信息找到每个目标主机的最佳负载。然后,它将使用全自动的情报收集、开发、后期开发和报告。它利用ML(和签名)来确定Web产品(情报收集)。显然,ML可以比签名更详细地确定所使用的平台/应用。然后,DeepExploit使用预先训练的模型来利用这一特定服务器[62] 。
[空行]
“Anticipate Data Manipulation Security Risks to AI Pipelines”
“AI as a Target and Tool: An Attacker’s Perspective on ML”
“How to Prepare for and Respond to Business Disruptions After Aggressive Cyberattacks”
“How to Prepare for Cyber Warfare”
“Zero Trust Is an Initial Step on the Roadmap to CARTA”
[空行]
[空行]
[空行]
[空行]
[空行]
1
2
3
4
5
6
7
8
9
10 “Augmented Reality Is the Operating System of the Future. AR Cloud Is How We Get There,”
11
12 “Could You Fire Someone in Virtual Reality?”
13 and “API Mediation Is the Key to Your Multiexperience Strategy”
14
15
16
17
18 “What Is CRISPR Gene Editing, and How Does It Work?”
19 “Universal Smart Contact Lenses Market 2018, Breathtaking CAGR of Approximately 10.4%, Foreseeing 2023,”
20 “AI Helps Electronic Nose Distinguish Scents,”
21 “The Eyes Have It,”
22 “Vagus Nerve Stimulator (VNS) Implantation for Children,”
23 “Military-Funded Study Successfully Tests ‘Prosthetic Memory’ Brain Implants,”
24 “Speech Synthesis From Neural Decoding of Spoken Sentences,”
25 “Elon Musk Hopes to Put a Computer Chip in Your Brain. Who Wants One?”
26 “The Untold Story of the ‘Circle of Trust’ Behind the World’s First Gene-Edited Babies,”
27
28 “Precautionary vs. Proactionary Principles,”
29 “Proactionary Principle,”
30 “AI Is Sending People to Jail — and Getting It Wrong,”
31 “Police Use Fitbit Data to Charge 90-Year-Old Man in Stepdaughter’s Killing,”
32 “The FBI Used a Suspect’s Face to Unlock His iPhone in Ohio Case,”
33
34 “Consumer Intelligence Series: Protect.me,”
35 “IEEE Global Initiative for Ethical Considerations in Artificial Intelligence (AI) and Autonomous Systems (AS) Drives, Together With IEEE Societies, New Standards Projects; Releases New Report on Prioritizing Human Well-Being,”
36
37
38 “2020 NASA Technology Taxonomy,”
39 “SAE International Releases Updated Visual Chart for Its ‘Levels of Driving Automation’ Standard for Self-Driving Vehicles,”
40 “Performance of Collaborative Robot Systems,”
41 “OFFensive Swarm-Enabled Tactics (OFFSET),”
42 “Inside the Olympics Opening Ceremony World-Record Drone Show,”
43 “SAFE SWARM,”
44 “Boeing Unveils ‘Loyal Wingman’ Drone,”
45 “National Robotics Initiative 2.0: Ubiquitous Collaborative Robots (NRI-2.0),”
46
47 “Norway’s Autonomous Ships Point to New Horizons,”
48 “Snake Robots Crawl to the Rescue, Part 1,”
49
50
51
52
53
54 “Certified Defenses for Data Poisoning Attacks,”
55 “Stealing Machine Learning Models via Prediction APIs,”
56 “Adversarial Vulnerability for Any Classifier,”
57
58
59
60 The ML behind thispersondoesnotexist.com “The AI Text Generator That’s Too Dangerous to Make Public,”
61 “AI Can Help Cybersecurity — If It Can Fight Through the Hype,”
62 GyoiThon